Kubernetes provides detailed insights about resource usage in the cluster. This is enabled by using Heapster, cAdvisor, InfluxDB and Grafana.
Heapster is installed as a cluster-wide pod. It gathers monitoring and events data for all pods on each node by talking to the Kubelet. Kubelet itself fetches this data from cAdvisor. This data is persisted in InfluxDB and then visualized using Grafana.
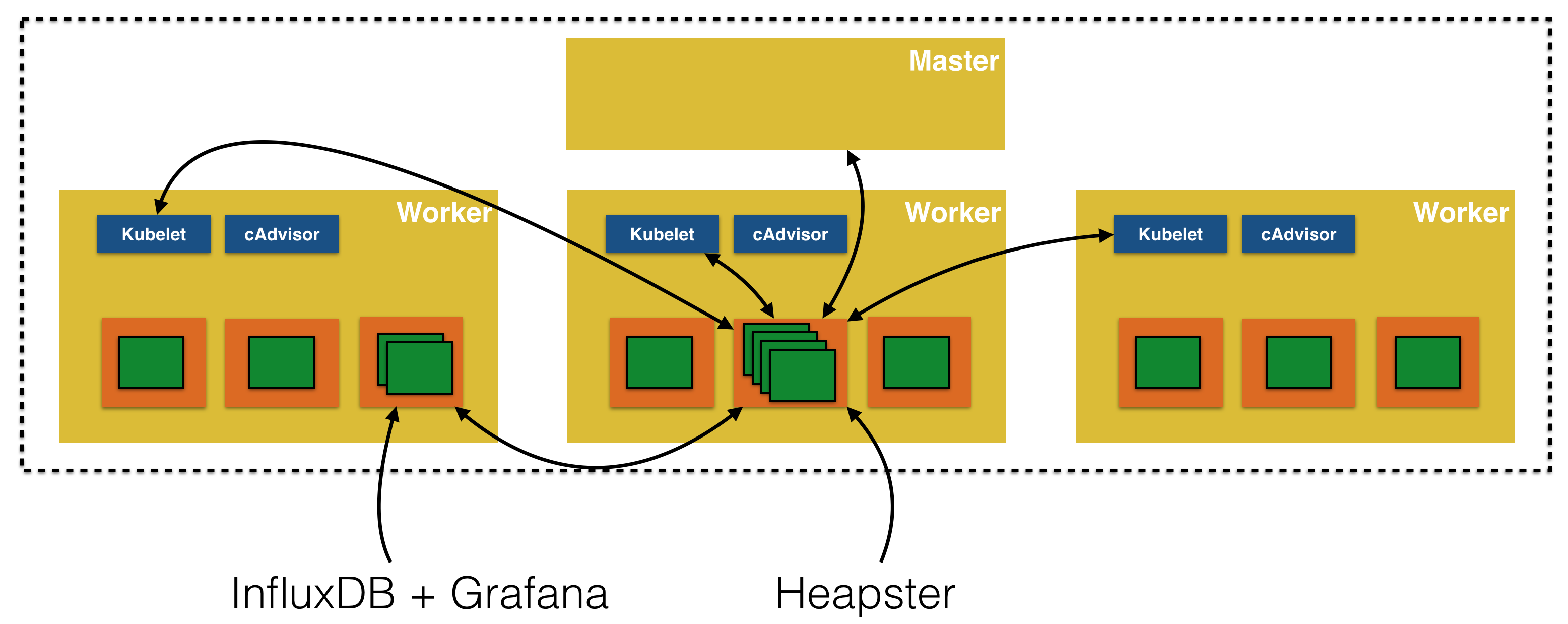
Resource Usage Monitoring provide more details about monitoring resources in Kubernetes.
Heapster, InfluxDB and Grafana are Kubernetes addons. They are enabled by default if you are running the cluster on Amazon Web Services or Google Cloud. But need to be explicitly enabled if the cluster is started using minikube or kops addons.
Start a Kubernetes cluster on Amazon Web Services as:
KUBERNETES_PROVIDER=aws; kube-up.sh
More details about starting a Kubernetes cluster are available at Getting Started with Kubernetes 1.4.
By default, it creates a 4-node Kubernetes cluster in us-west-2a region. More details about the cluster can be seen using the command kubectl cluster-info and it shows the results as:
Kubernetes master is running at https://35.165.6.91 Elasticsearch is running at https://35.165.6.91/api/v1/proxy/namespaces/kube-system/services/elasticsearch-logging Heapster is running at https://35.165.6.91/api/v1/proxy/namespaces/kube-system/services/heapster Kibana is running at https://35.165.6.91/api/v1/proxy/namespaces/kube-system/services/kibana-logging KubeDNS is running at https://35.165.6.91/api/v1/proxy/namespaces/kube-system/services/kube-dns kubernetes-dashboard is running at https://35.165.6.91/api/v1/proxy/namespaces/kube-system/services/kubernetes-dashboard Grafana is running at https://35.165.6.91/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana InfluxDB is running at https://35.165.6.91/api/v1/proxy/namespaces/kube-system/services/monitoring-influxdb To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Note the URL for the Grafana service. Open this URL in a browser window. You’ll be prompted for an invalid certificate warning but this can be safely ignored at this time. In production system, appropriate certificates should be installed.
Then you’ll be prompted for credentials. These can be obtained using kubectl config view command. It will show the output as:
- name: aws_kubernetes-basic-auth
user:
password: ZeH4JpQzAtGDEBdb
username: adminUse the value from username and password fields.
This shows the default dashboard:
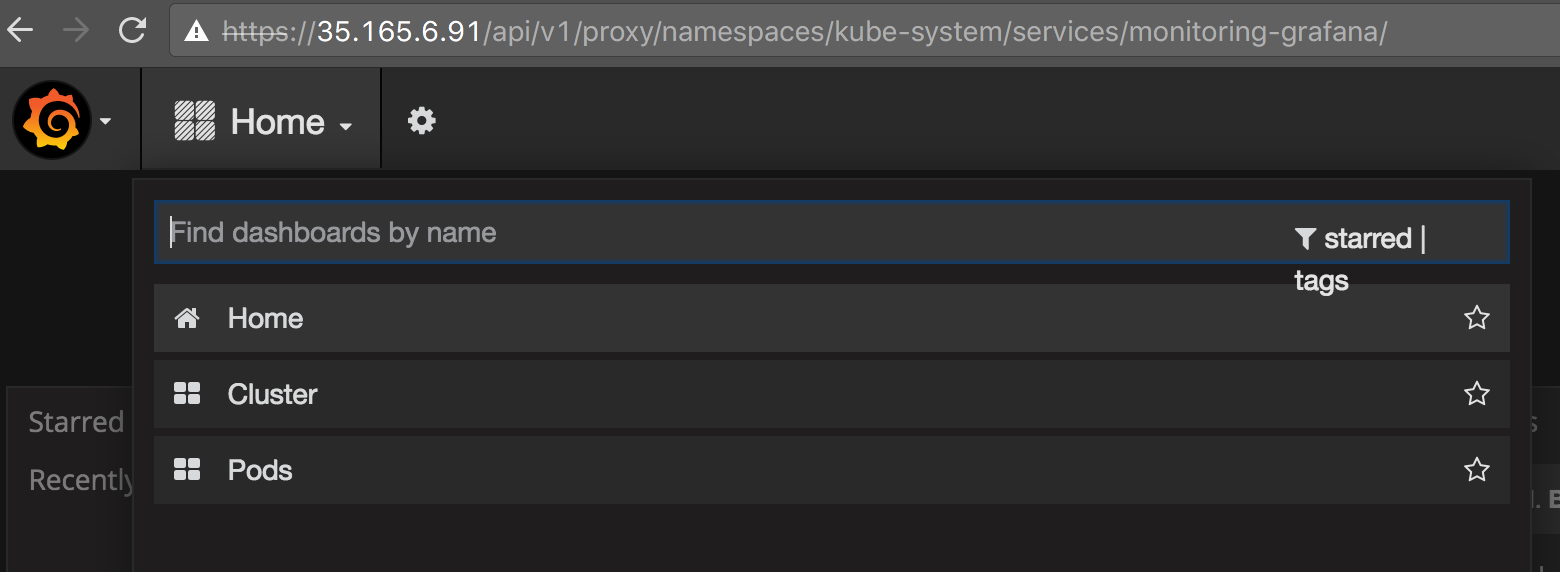
It consists of two dashboards – one for cluster and another for pods.
For this blog, a 4-node Couchbase cluster was created following the steps outlined in Create a Couchbase Cluster using Kubernetes.
A cluster-wide dashboard shows CPU, Memory, Filesystem and Network usage across all the hosts and looks like:
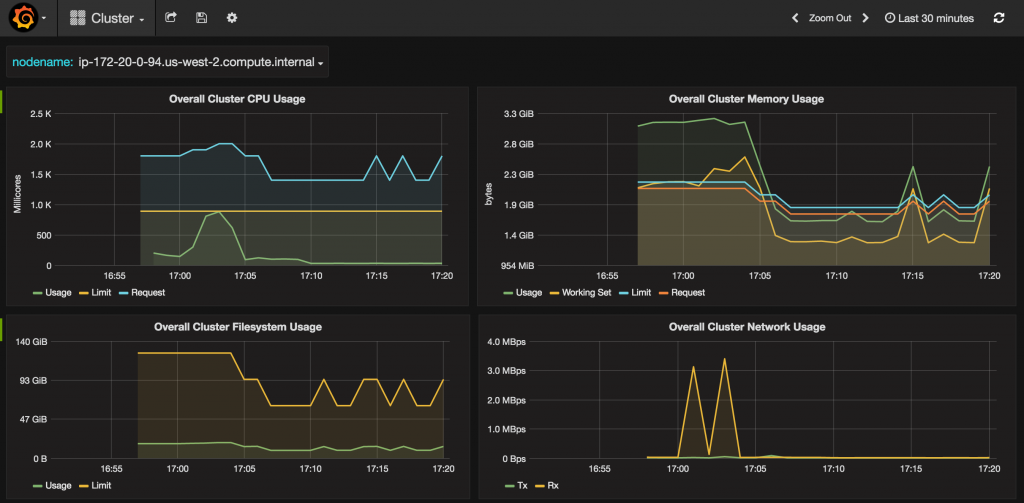
CPU, memory, filesystem and network usage for all nodes may be seen:
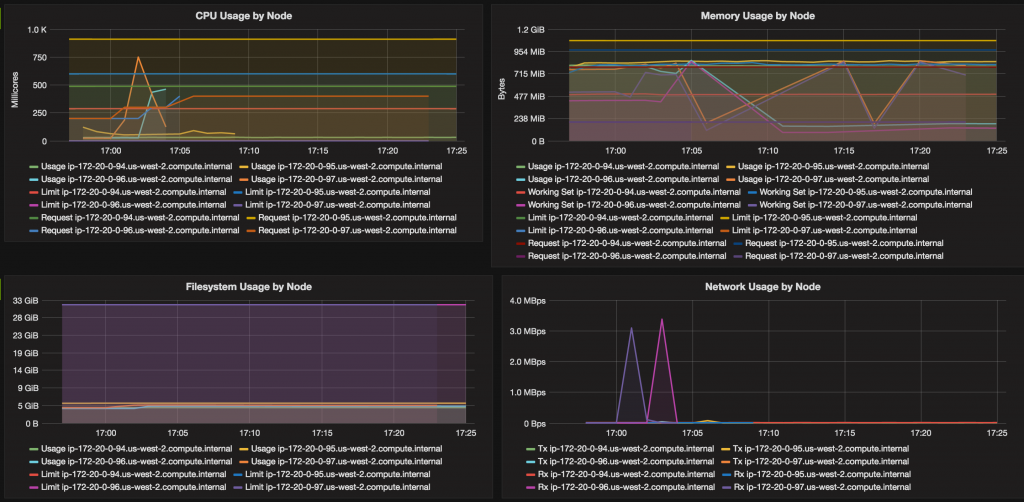
Details for each node may be seen by selecting the node:
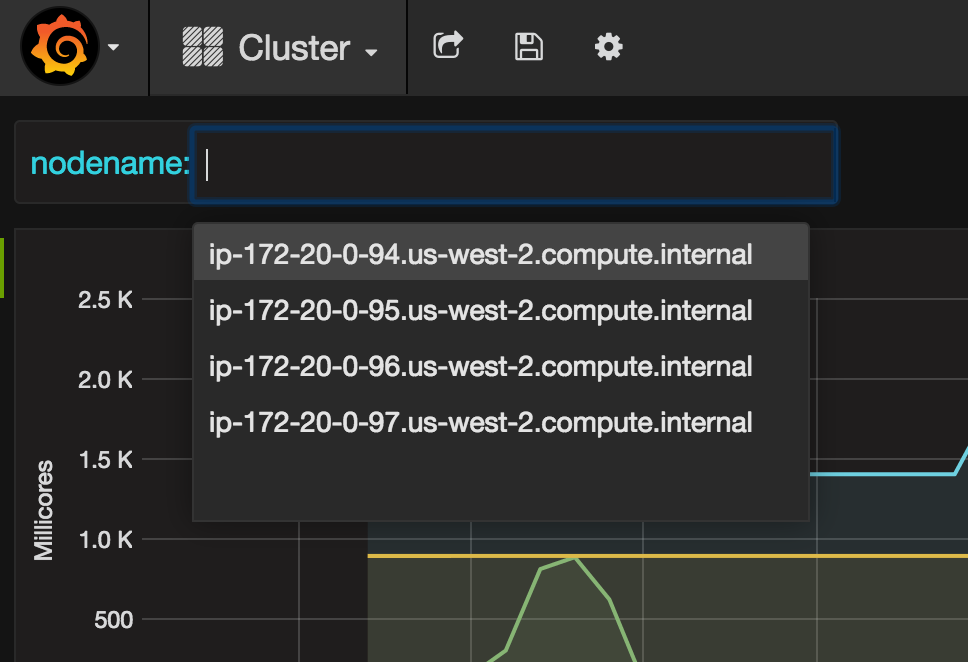
CPU, memory, filesystem and network usage for each node is displayed:
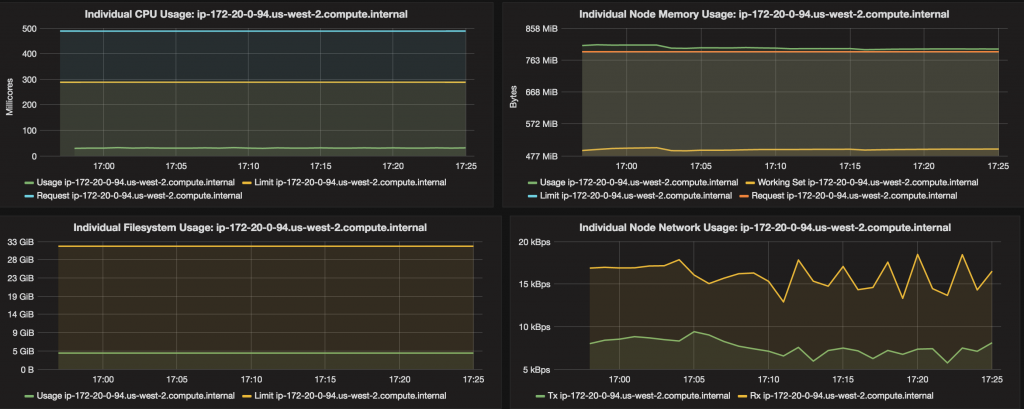
Pods dashboard shows CPU, memory, filesystem and network usage for each pod:
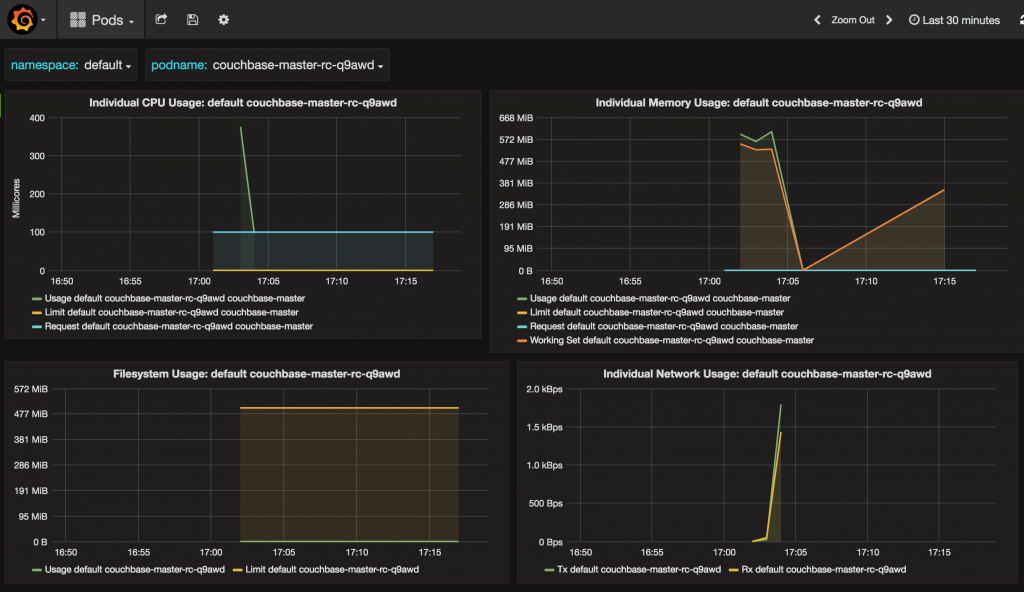
A different pod may be chosen:
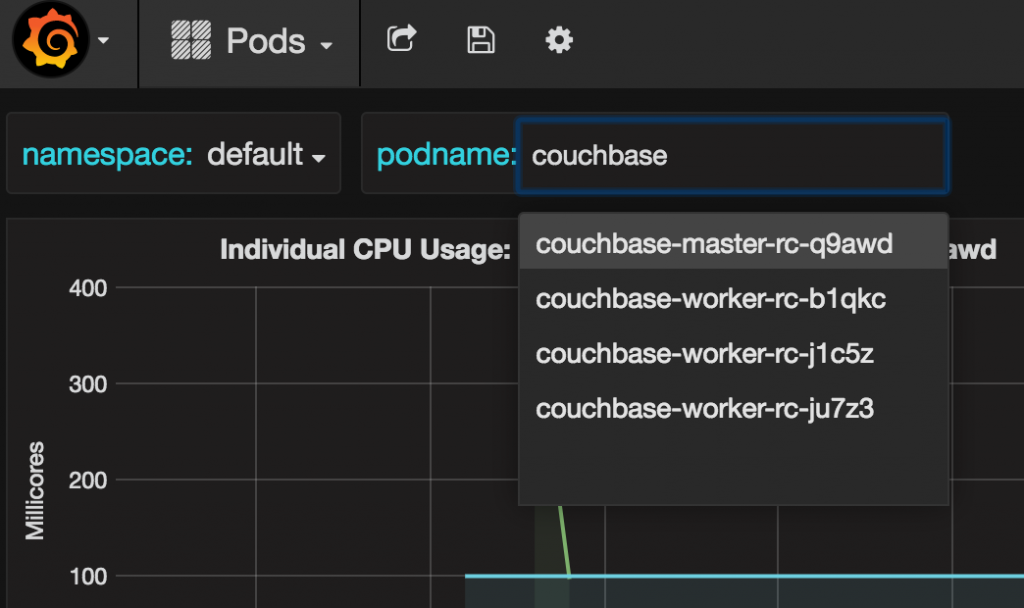
A complete list of all services running in the Kubernetes can be seen using kubectl get services --all-namespaces command. It shows the output as:
kubectl.sh get svc --all-namespaces NAMESPACE NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE default couchbase-master-service 10.0.70.206 aef06961eb8f3... 8091/TCP 1h default kubernetes 10.0.0.1 443/TCP 1h kube-system elasticsearch-logging 10.0.54.112 9200/TCP 1h kube-system heapster 10.0.146.18 80/TCP 1h kube-system kibana-logging 10.0.123.37 5601/TCP 1h kube-system kube-dns 10.0.0.10 53/UDP,53/TCP 1h kube-system kubernetes-dashboard 10.0.146.179 80/TCP 1h kube-system monitoring-grafana 10.0.33.81 80/TCP 1h kube-system monitoring-influxdb 10.0.26.251 8083/TCP,8086/TCP 1h
A complete list of all the pods running in the Kubernetes cluster can be seen using kubectl get pods --all-namespaces. It shows the output as:
kubectl.sh get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE default couchbase-master-rc-q9awd 1/1 Running 17 56m default couchbase-worker-rc-b1qkc 1/1 Running 15 54m default couchbase-worker-rc-j1c5z 1/1 Running 17 52m default couchbase-worker-rc-ju7z3 1/1 Running 15 52m kube-system elasticsearch-logging-v1-18ylh 1/1 Running 0 1h kube-system elasticsearch-logging-v1-fupap 1/1 Running 0 1h kube-system fluentd-elasticsearch-ip-172-20-0-94.us-west-2.compute.internal 1/1 Running 0 1h kube-system fluentd-elasticsearch-ip-172-20-0-95.us-west-2.compute.internal 1/1 Running 0 1h kube-system fluentd-elasticsearch-ip-172-20-0-96.us-west-2.compute.internal 1/1 Running 15 1h kube-system fluentd-elasticsearch-ip-172-20-0-97.us-west-2.compute.internal 1/1 Running 17 1h kube-system heapster-v1.2.0-1374379659-jms8e 4/4 Running 0 1h kube-system kibana-logging-v1-fcg4b 1/1 Running 3 1h kube-system kube-dns-v20-wpip4 3/3 Running 0 1h kube-system kube-proxy-ip-172-20-0-94.us-west-2.compute.internal 1/1 Running 0 1h kube-system kube-proxy-ip-172-20-0-95.us-west-2.compute.internal 1/1 Running 0 1h kube-system kube-proxy-ip-172-20-0-96.us-west-2.compute.internal 1/1 Running 15 1h kube-system kube-proxy-ip-172-20-0-97.us-west-2.compute.internal 1/1 Running 17 1h kube-system kubernetes-dashboard-v1.4.0-yxxgx 1/1 Running 0 1h kube-system monitoring-influxdb-grafana-v4-7asy4 2/2 Running 0 1h
Some references:
- Kubernetes Resource Monitoring
- Couchbase Cluster using Kubernetes, Docker Swarm, DC/OS and Amazon ECS
- Follow us @couchbasedev
| Reference: | Kubernetes Monitoring with Heapster, InfluxDB and Grafana from our JCG partner Arun Gupta at the Miles to go 3.0 … blog. |

