In a previous blog post I mentioned that I wanted to extract blips from The ThoughtWorks Radar into a CSV file and I thought this would be a good mini project for me to practice using Go.
In particular I wanted to try using channels and this seemed like a good chance to do that.
I watched a talk by Rob Pike on designing concurrent applications where he uses the following definition of concurrency:
Concurrency is a way to structure a program by breaking it into pieces that can be executed independently.
He then demonstrates this with the following diagram:
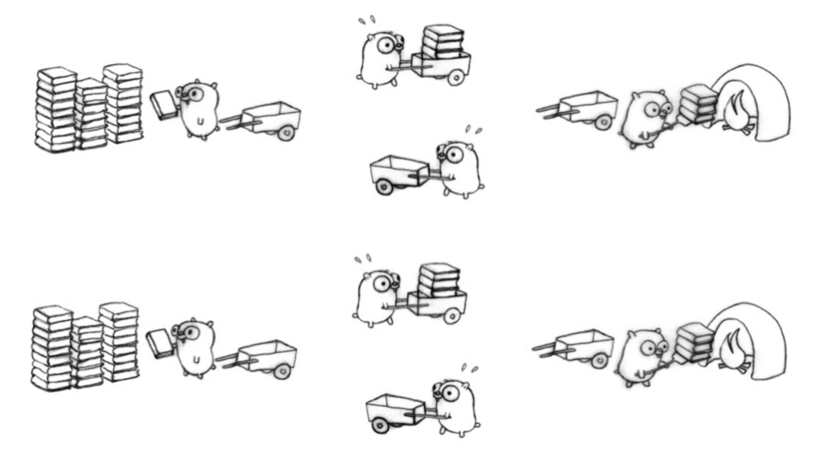
I broke the scraping application down into four parts:
- Find the links of blips to download ->
- Download the blips ->
- Scrape the data from each page ->
- Write the data into a CSV file
I don’t think we gain much by parallelising steps 1) or 4) but steps 2) and 3) seem easily parallelisable. Therefore we’ll use a single goroutine for steps 1) and 4) and multiple goroutines for steps 2) and 3).
We’ll create two channels:
- filesToScrape
- filesScraped
And they will interact with our components like this:
- 2) will write the path of the downloaded files into filesToScape
- 3) will read from filesToScrape and write the scraped content into filesScraped
- 4) will read from filesScraped and put that information into a CSV file.
I decided to write a completely serial version of the scraping application first so that I could compare it to the parallel version. I had the following common code:
scrape/scrape.go
package scrape
import (
"github.com/PuerkitoBio/goquery"
"os"
"bufio"
"fmt"
"log"
"strings"
"net/http"
"io"
)
func checkError(err error) {
if err != nil {
fmt.Println(err)
log.Fatal(err)
}
}
type Blip struct {
Link string
Title string
}
func (blip Blip) Download() File {
parts := strings.Split(blip.Link, "/")
fileName := "rawData/items/" + parts[len(parts) - 1]
if _, err := os.Stat(fileName); os.IsNotExist(err) {
resp, err := http.Get("http://www.thoughtworks.com" + blip.Link)
checkError(err)
body := resp.Body
file, err := os.Create(fileName)
checkError(err)
io.Copy(bufio.NewWriter(file), body)
file.Close()
body.Close()
}
return File{Title: blip.Title, Path: fileName }
}
type File struct {
Title string
Path string
}
func (fileToScrape File ) Scrape() ScrapedFile {
file, err := os.Open(fileToScrape.Path)
checkError(err)
doc, err := goquery.NewDocumentFromReader(bufio.NewReader(file))
checkError(err)
file.Close()
var entries []map[string]string
doc.Find("div.blip-timeline-item").Each(func(i int, s *goquery.Selection) {
entry := make(map[string]string, 0)
entry["time"] = s.Find("div.blip-timeline-item__time").First().Text()
entry["outcome"] = strings.Trim(s.Find("div.blip-timeline-item__ring span").First().Text(), " ")
entry["description"] = s.Find("div.blip-timeline-item__lead").First().Text()
entries = append(entries, entry)
})
return ScrapedFile{File:fileToScrape, Entries:entries}
}
type ScrapedFile struct {
File File
Entries []map[string]string
}
func FindBlips(pathToRadar string) []Blip {
blips := make([]Blip, 0)
file, err := os.Open(pathToRadar)
checkError(err)
doc, err := goquery.NewDocumentFromReader(bufio.NewReader(file))
checkError(err)
doc.Find(".blip").Each(func(i int, s *goquery.Selection) {
item := s.Find("a")
title := item.Text()
link, _ := item.Attr("href")
blips = append(blips, Blip{Title: title, Link: link })
})
return blips
}Note that we’re using the goquery library to scrape the HTML files that we download.
A Blip is used to represent an item that appears on the radar e.g. .NET Core. A File is a representation of that blip on my local file system and a ScrapedFile contains the local representation of a blip and has an array containing every appearance the blip has made in radars over time.
Let’s have a look at the single threaded version of the scraper:
cmd/single/main.go
package main
import (
"fmt"
"encoding/csv"
"os"
"github.com/mneedham/neo4j-thoughtworks-radar/scrape"
)
func main() {
var filesCompleted chan scrape.ScrapedFile = make(chan scrape.ScrapedFile)
defer close(filesCompleted)
blips := scrape.FindBlips("rawData/twRadar.html")
var filesToScrape []scrape.File
for _, blip := range blips {
filesToScrape = append(filesToScrape, blip.Download())
}
var filesScraped []scrape.ScrapedFile
for _, file := range filesToScrape {
filesScraped = append(filesScraped, file.Scrape())
}
blipsCsvFile, _ := os.Create("import/blipsSingle.csv")
writer := csv.NewWriter(blipsCsvFile)
defer blipsCsvFile.Close()
writer.Write([]string{"technology", "date", "suggestion" })
for _, scrapedFile := range filesScraped {
fmt.Println(scrapedFile.File.Title)
for _, blip := range scrapedFile.Entries {
writer.Write([]string{scrapedFile.File.Title, blip["time"], blip["outcome"] })
}
}
writer.Flush()
}rawData/twRadar.html is a local copy of the A-Z page which contains all the blips. This version is reasonably simple: we create an array containing all the blips, scrape them into another array, and then that array into a CSV file. And if we run it:
$ time go run cmd/single/main.go real 3m10.354s user 0m1.140s sys 0m0.586s $ head -n10 import/blipsSingle.csv technology,date,suggestion .NET Core,Nov 2016,Assess .NET Core,Nov 2015,Assess .NET Core,May 2015,Assess A single CI instance for all teams,Nov 2016,Hold A single CI instance for all teams,Apr 2016,Hold Acceptance test of journeys,Mar 2012,Trial Acceptance test of journeys,Jul 2011,Trial Acceptance test of journeys,Jan 2011,Trial Accumulate-only data,Nov 2015,Assess
It takes a few minutes and most of the time will be taken in the blip.Download() function – work which is easily parallelisable. Let’s have a look at the parallel version where goroutines use channels to communicate with each other:
cmd/parallel/main.go
package main
import (
"os"
"encoding/csv"
"github.com/mneedham/neo4j-thoughtworks-radar/scrape"
)
func main() {
var filesToScrape chan scrape.File = make(chan scrape.File)
var filesScraped chan scrape.ScrapedFile = make(chan scrape.ScrapedFile)
defer close(filesToScrape)
defer close(filesScraped)
blips := scrape.FindBlips("rawData/twRadar.html")
for _, blip := range blips {
go func(blip scrape.Blip) { filesToScrape <- blip.Download() }(blip)
}
for i := 0; i < len(blips); i++ {
select {
case file := <-filesToScrape:
go func(file scrape.File) { filesScraped <- file.Scrape() }(file)
}
}
blipsCsvFile, _ := os.Create("import/blips.csv")
writer := csv.NewWriter(blipsCsvFile)
defer blipsCsvFile.Close()
writer.Write([]string{"technology", "date", "suggestion" })
for i := 0; i < len(blips); i++ {
select {
case scrapedFile := <-filesScraped:
for _, blip := range scrapedFile.Entries {
writer.Write([]string{scrapedFile.File.Title, blip["time"], blip["outcome"] })
}
}
}
writer.Flush()
}Let’s remove the files we just downloaded and give this version a try.
$ rm rawData/items/* $ time go run cmd/parallel/main.go real 0m6.689s user 0m2.544s sys 0m0.904s $ head -n10 import/blips.csv technology,date,suggestion Zucchini,Oct 2012,Assess Reactive Extensions for .Net,May 2013,Assess Manual infrastructure management,Mar 2012,Hold Manual infrastructure management,Jul 2011,Hold JavaScript micro frameworks,Oct 2012,Trial JavaScript micro frameworks,Mar 2012,Trial NPM for all the things,Apr 2016,Trial NPM for all the things,Nov 2015,Trial PowerShell,Mar 2012,Trial
So we’re down from 190 seconds to 7 seconds, pretty cool! One interesting thing is that the order of the values in the CSV file will be different since the goroutines won’t necessarily come back in the same order that they were launched. We do end up with the same number of values:
$ wc -l import/blips.csv
1361 import/blips.csv
$ wc -l import/blipsSingle.csv
1361 import/blipsSingle.csv$ wc -l import/blips.csv 1361 import/blips.csv $ wc -l import/blipsSingle.csv 1361 import/blipsSingle.csv
And we can check that the contents are identical:
$ cat import/blipsSingle.csv | sort > /tmp/blipsSingle.csv $ cat import/blips.csv | sort > /tmp/blips.csv $ diff /tmp/blips.csv /tmp/blipsSingle.csv
$ cat import/blipsSingle.csv | sort > /tmp/blipsSingle.csv $ cat import/blips.csv | sort > /tmp/blips.csv $ diff /tmp/blips.csv /tmp/blipsSingle.csv
The code in this post is all on github. I’m sure I’ve made some mistakes/there are ways that this could be done better so do let me know in the comments or I’m @markhneedham on twitter.
| Reference: | Go: First attempt at channels from our JCG partner Mark Needham at the Mark Needham Blog blog. |
