What is an editor?
An editor is, for me, the main tool I use for work. As a Language Engineer I create new languages, I use existing ones and I need different tools to work with them. I would like to be able to hack all of them together, in a customized IDE I can grow for me. This is why I am working on Kanvas, the hackable editor. Which is on GitHub, of course.
In many cases I need a simple text editor for my DSLs and I tend to build them using ANTLR. I will need other stuff, like tabular or graphical projections, simulators and more but I need to start somewhere, right? Also, I think right now there is not an easy way to get a standalone editor for a DSL, with minimal dependencies and a simple structure. There is not a light option on the menu. Time to add one.
Getting an editor from your grammar quickly
Once you define the grammar of your language there is a lot of information you can extract from it. I think you should be able to get as much value as possible from it for free, with the possibility to customize it further, if needed. This is similar to the idea behind Xtext (minus the 400 pages you need to read to understand EMF).
How quickly can you get an editor for your ANTLR grammar? You create a new project for your editor, add Kanvas as a dependency and register which languages do you intend to support:
fun main(args: Array<String>) {
languageSupportRegistry.register("sm", smLangSupport)
val kanvas = Kanvas()
SwingUtilities.invokeLater {
kanvas.createAndShowKanvasGUI()
kanvas.addTab("My SM", languageSupport = smLangSupport)
}and add these lines to support your language:
object smLangSupport : BaseLanguageSupport() {
override val antlrLexerFactory: AntlrLexerFactory
get() = object : AntlrLexerFactory {
override fun create(code: String): Lexer = SMLexer(org.antlr.v4.runtime.ANTLRInputStream(code))
}
override val parserData: ParserData?
get() = ParserData(SMParser.ruleNames, SMParser.VOCABULARY, SMParser._ATN)
}This quickly. Less then 10 lines of code. We just need to specify the Lexer and Parser classes (SMLexer and SMParser in this example).
If you are wondering what language is that, that is Kotlin: a concise static language for the JVM, easily interoperable with Java.
Let’s improve it a little bit: syntax highlighting
So I have a simple language, I get an editor basically for free and I start using it. As first thing I want to define the style for the different kind of tokens. We are doing something simple, just setting the colors:
object smLangSyntaxScheme : SyntaxScheme(true) {
override fun getStyle(index: Int): Style {
val style = Style()
val color = when (index) {
// Types
SMLexer.STRING, SMLexer.INT, SMLexer.DECIMAL -> Color(42, 53, 114)
// Literals
SMLexer.STRINGLIT -> Color(21, 175, 36)
SMLexer.INTLIT, SMLexer.DECLIT -> Color.BLUE
// Comments
SMLexer.COMMENT -> Color(170, 181, 171)
// Operators
SMLexer.ASTERISK, SMLexer.DIVISION, SMLexer.PLUS, SMLexer.MINUS -> Color.WHITE
// Keywords
SMLexer.VAR -> Color.GREEN
SMLexer.INPUT -> Color(200, 250, 200)
SMLexer.SM -> Color(200, 250, 200)
SMLexer.EVENT -> Color(200, 250, 200)
SMLexer.AS -> Color(50, 12, 96)
// Identifiers
SMLexer.ID -> Color.MAGENTA
// Separators
SMLexer.ARROW -> Color(50, 12, 96)
SMLexer.COLON -> Color(50, 12, 96)
SMLexer.ASSIGN -> Color(50, 12, 96)
SMLexer.LPAREN, SMLexer.RPAREN -> Color.WHITE
// Rest
SMLexer.UNMATCHED -> Color.RED
else -> null
}
if (color != null) {
style.foreground = color
}
return style
}
}We are not setting certain tokens to be bold or in italic because we want to keep things simple. By the way, if you are interested in how syntax highlighting works in Kanvas, I described it in this post.
And then comes autocompletion
Now, we get some limited autocompletion for free. We basically get autocompletion depending on the structure of the language, so our algorithm can tell us which keywords can be inserted in the current position or that in a certain position an identifier can be accepted. What the algorithm cannot not determine for free is which identifiers should suggest. Let’s implement a very simple logic: when we can insert an identifier we look at the preceeding tokens and use them to determine which suggestion to make. For example, when defining an input we could suggest “anInput” while when defining a variable we could suggest “aVar”:
override val propositionProvider: PropositionProvider
get() = object : PropositionProvider {
override fun fromTokenType(completionProvider: CompletionProvider,
preecedingTokens: List<Token>, tokenType: Int): List<Completion> {
val res = LinkedList<Completion>()
var proposition : String? = this@smLangSupport.parserData!!.vocabulary.getLiteralName(tokenType)
if (proposition != null) {
if (proposition.startsWith("'") && proposition.endsWith("'")) {
proposition = proposition.substring(1, proposition.length - 1)
}
res.add(BasicCompletion(completionProvider, proposition))
} else {
when (tokenType) {
SMParser.ID -> {
val determiningToken = preecedingTokens.findLast { setOf(SMLexer.SM, SMLexer.VAR, SMLexer.EVENT, SMLexer.INPUT).contains(it.type) }
val text = when (determiningToken?.type) {
SMLexer.SM -> "aStateMachine"
SMLexer.EVENT -> "anEvent"
SMLexer.INPUT -> "aInput"
SMLexer.VAR -> "aVar"
else -> "someID"
}
res.add(BasicCompletion(completionProvider, text))
}
}
}
return res
}
}Here is the code. Is this enough? I do not know, but what I know is that this is a system small enough to be understandable and simple enough to be easily extended and customized. So I plan to use it for this small language, and improve the autocompletion as needed, specifically for this language. Organically and iteratively grow tool support is the name of the game.
Design goals: something similar to Sublime Text but open-source
We all love Sublime Text. I would like to have something inspired to it, but open-source. Why open-source? So that I can customize it as much as I want.
This is how it looks like for now:
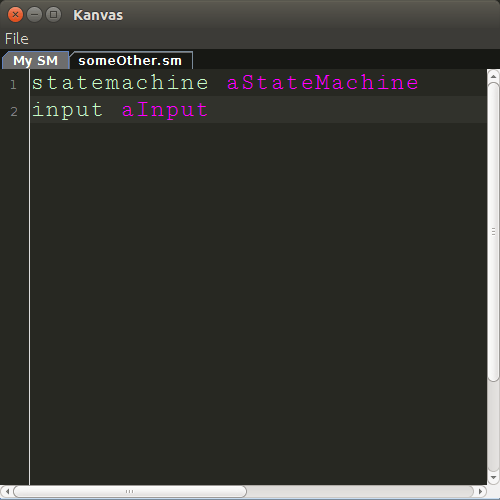
Yes, it is not yet as beautiful as Sublime Text. But this means I have space for improvement.
To Language Workbench or to not Language Workbench?
I work routinely with Language Workbenches such as Jetbrains MPS and Xtext. They are great because they permit to obtain very good tool support very quickly. In many situations they are your best option. However, as every engineering choice, there are different aspects to consider. Jetbrains MPS and Xtext are very large and complex pieces of software, the kind of stuff that weight hundreds of MBs. To learn the internals of these platforms require a lot of work and a large effort. You can have a huge benefit by simply using those platforms. However they are not the best solution in all situations because in some situations you need to integrate your language with existing systems and thus you have to bend those Language Workbenches in ways they are not designed to. Maybe you want to embed your editor or tools in your existing platform, maybe you want to have a simple editor to use on a tablet, maybe you want tools to use from the command line. Maybe you want to hack a system together to fit your particular needs in some peculiar way. In those cases using a Language Workbench is not the right choice. You need something simple, something hackable. This is the approach I am experimenting it. To do that I am working on a few open-source projects and writing a book.
Conclusions
Will this fly? I do not know. I am having fun spending the few time I find on this project. And I feel it can be a good approach to get simple standalone editors for DSLs built with ANTLR. I would also like to use it as my sort of Kotlin-powered vim, a vim for the new millenium. With super-projectional-powers. Let’s see how this grows.
And yes, I know that Atom describes itself as the hackable editor. But it is not hackable enough from my point of view.
| Reference: | Kanvas: generating a simple IDE from your ANTLR grammar from our JCG partner Federico Tomassetti at the Federico Tomassetti blog. |
