Pentaho Data Integration (PDI) provides the ETL capabilities that facilitate the process of capturing, cleansing, and storing data. Its uniform and consistent format makes it accessible and relevant to end-users and IoT technologies.
Apache Drill is a schema-free SQL-on-Hadoop engine that lets you run SQL queries against different data sets with various formats, e.g. JSON, CSV, Parquet, HBase, etc. By integrating it with PDI, you have the flexibility to do serious data integration work through Pentaho’s powerful PDI product. The Drill Tutorials pages in MapR’s documentation can help you get familiar with Apache Drill.
Step 1
You’ll need administrator permissions in order to do these steps. Make sure that you meet the following software requirements:
- MapR Converged Data Platform (version 4.x or 5.x)
- Apache Drill (version 1.6 or later) along with the latest Drill JDBC driver
- Support of the Apache Drill driver is provided through MapR.
- Apache ZooKeeper (running in replicated mode)
- Pentaho Data Integration (version 5.4 or later)
You should also make sure that the PDI client system can resolve the hostnames on your Drill cluster before you get started.
Step 2
The first thing you’ll have to do is get the Drill cluster ID and construct a custom URL string. This will be something that we’ll be using a bit later to make the JDBC connection through PDI.
- Getting the Drill cluster ID isn’t too bad: all you have to do is go to the query page in the Drill interface and run an SQL query like this:
select string_val from sys.boot where name =’drill.exec.cluster-id’;
- Apache Drill will return your cluster ID. Once you have that, you can make a custom URL that will end up looking something like this:
jdbc:drill:zk=mapr1:5181,mapr2:5181,mapr3:5181/drill/WhateverYourClusterIDIs
Step 3
Once you have your custom URL string, follow these steps to make the connection to PDI:
- Open PDI, start a new Transformation, then click on the View tab in the far left.
- Expand Transformation 1, then right-click on Database connections and select New.
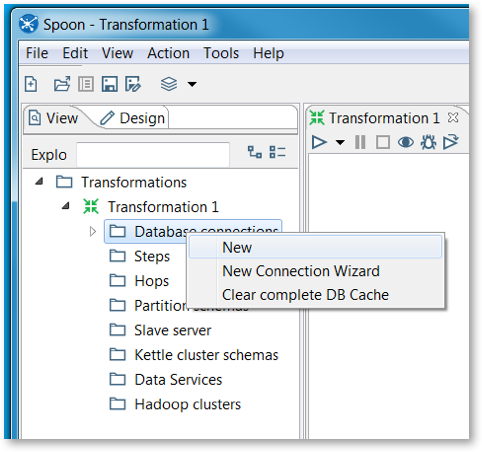
- Do the following in the Database Connection window:
- Name the connection. We are using Drill as the Connection Name in our example below.
- Select Generic Database for your database type and Native JDBC for your access type.
- Under Settings on the right, copy and paste your Custom Connection URL.
- Enter the Custom Driver Class Name.
- Leave the username and password fields empty for now.
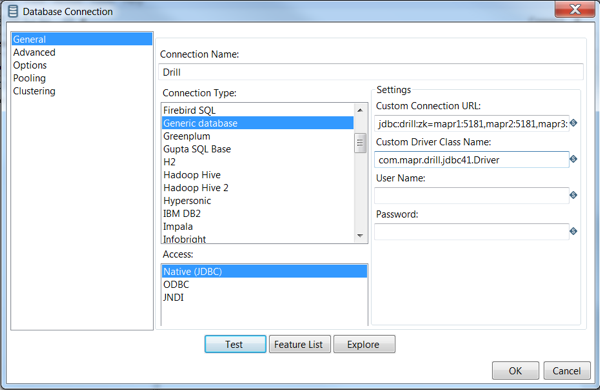
- Click Test to verify the connection. You should see a connection success window pop up.
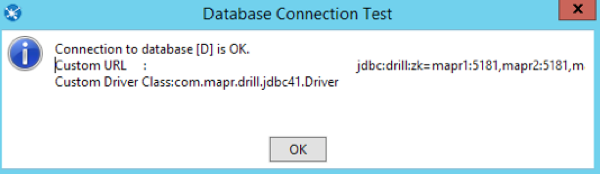
Troubleshooting Tips
On the off-chance that your connection test doesn’t work, try verifying that your Custom URL string is correct, and make sure your hosts file for the PDI client can resolve the private hostnames of the cluster.
Summary
By the time you get to the end of this process, you should have successfully connected your Pentaho Data Integration client to your MapR cluster using Apache Drill. Have fun with your data!
| Reference: | Connecting Pentaho Data Integration to MapR Using Apache Drill from our JCG partner Sandra Wagner at the Mapr blog. |

Valuable information! Looking forward to seeing your notes posted. Thank you for sharing the nice article. Good to see your article.