Intro
In the first part I explained the theoretical approach to log analysis that I think is best for a sustain engineer. This engineer doesn’t need to analyze logs immediately as they come but instead is focused on a deep analysis of complicated issues. In this second part I’ll show that many search scenarios can be covered with one sophisticated template and show a working prototype.
Search Object Template
The main requirement for the search template is it must be sophisticated, very sophisticated in the best case. The less manual search the better. A sophisticated template should do most of the work and do it fast. As we don’t have any servers here only the developer’s PC which is expected to handle 2-3 GB of logs speed is also important.
Main Regular Expressions
The template should declare some regular expressions which will be searched for (with Matcher.find) in the logs. If more than one is declared first the results for the first are collected, then for the second etc. In the most general sense the result of a search is an array of String – List<String>.
Acceptance Criteria
Not all results are accepted by the searching process. For example the engineer can search for all connection types excluding “X”. Then he or she can create an acceptance criterion and filter them out. by specifying a regex “any type but X”. Another possibility is searching within a time interval. The engineer can search for any log record between 10 and 12 hours (he or she has to enter the complete dates of course).
Looking for distinct expressions is also possible. In this case the engineer specifies one more regular expression (more than one in the general case). An example will explain this concept better.
distinct regex:
connection type (q|w)
log records found by the main regex:
connection type w found connection type q created connection type s destroyed connection type q found
The result of a distinct search:
connection type w found connection type q created
Parameters
One of the issues with regular expressions is that really useful regular expressions are very long and unwieldy. Here is a sample date from a log:
2018-08-06 10:32:12.234
And here is the regex for it:
\d\d\d\d-\d\d-\d\d \d\d:\d\d:\d\d.\d\d\d
The solution is quite simple – use substitution. I call them parameters for the regex. Some parameters may be static like the time for the record but some may be defined by the user. Immediately before the execution the parameters are replaced with the actual values.
Views
The result of the search is a log record i.e. something like
2018-08-06 10:32:12.234 [Thread-1] DEBUG - Connection 1234 moved from state Q to state W \r?\n
While it is great to find what was defined in the template it would be even better to divide the information into useful pieces. For example this table represents all the useful information from this record in a clear and concise way:
| Connection | 1234 | Q | -> | W |
|---|
To extract this information pieces we can use the “view” approach. This means declaring smaller regexes that are searched for in the log record and return a piece of information about the log record. It is like a view of this log record. Showing it all in a table makes it easier to read. Also a table can be sorted by any column.
Sort and Merge
The most efficient way to make this kind of search with the template is use a thread pool and assign every thread to a log file. Assuming there are 3-4 threads in the pool the search will work 3-4 times faster. But merging results becomes an important issue. There can be 2 solutions here:
- Merging results. We need to make sure that the results go in the correct order. If we have 3 log files, the first one covering 10-12 hours, the second 12-14, the third 14-17 then the search results from those file must go in the same order. This is called merging.
- Sorting results. Instead of merging them we can just sort them by date and time. Less sophisticated but simple.
Merging looks like a more advanced technique which allows us to keep the original order of records.
Workflow
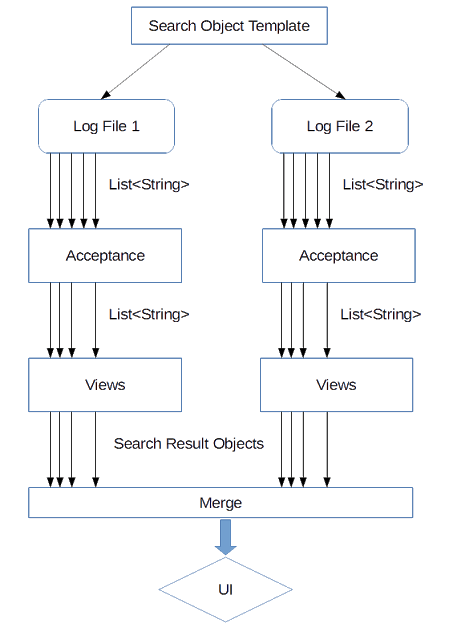
Final Thoughts
The question that must be nagging everyone who has reached this point in this post is: Has anyone tried to implement all this? The answer is yes! There is a working application that is based on the Eclipse framework, includes a Spring XML config and a lot of other stuff. The search object templates work as described in this article.
Here is the Github link:
https://github.com/xaltotungreat/regex-analyzer-0
Why 0? Well it was meant to be a prototype and to some extent is still is. I called this application REAL
Regular
Expressions
Analyzer
for Logs
It is assumed the user has some knowledge how to export an Eclipse RCP application or launch it from within the Eclipse IDE. Unfortunately I didn’t have enough time to write any good documentation about it. By default it can analyze HBase logs and there are a lot of examples in the config folder.
| Published on Java Code Geeks with permission by Vadim Korkin, partner at our JCG program. See the original article here: IDE approach to log analysis pt. 2 Opinions expressed by Java Code Geeks contributors are their own. |
