Ack: This article is a remix of stuff learned from personal experience as well as from multiple other sources on serverless security. I cannot list down or acknowledge all of them here; nevertheless, special thanks should go to The Register, Hacker Noon, PureSec, and the Serverless Status and Serverless (Cron)icle newsletters.
We all love to imagine that our systems are secure. And then…
BREACH!!!
A very common nightmare shared by every developer, sysadmin and, ultimately, CISO.

Inevitable?
One basic principle of computer security states that no system can attain absolute security. Just like people: nobody is perfect. Not unless it is fully isolated from the outside; which, by today’s standards, is next to impossible – besides, what’s the point of having a system that cannot take inputs and provide outputs?
Whatever advanced security precaution you take, attackers will eventually find a way around. Even if you use the most stringent encryption algorithm with the longest possible key size, attackers will eventually brute-force their way through; although it could be time-wise infeasible at present, who can guarantee that a bizaare technical leap would render it possible tomorrow, or the next day?
But it’s not the brute-force that you should really be worried about: human errors are way more common, and can have devastating effects on systems security; much more so than a brute-forced passkey. Just have a peek at this story where some guys just walked into the U.S. IRS building and siphoned out millions of dollars, without using a single so-called “hacking” technique.
As long as systems are made and operated by people—who are error-prone by nature—they will never be truly secure.

So, are we doomed?
No.
Ever seen the insides of a ship?
How its hull is divided into compartments—so that one leaking compartment does not cause the whole ship to sink?
People often apply a similar concept in designing software: multiple modules so that one compromised module doesn’t bring the whole system down.
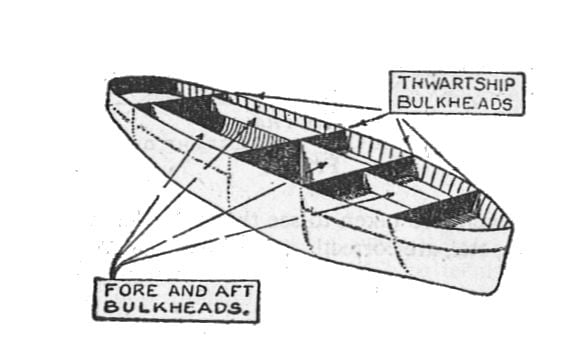
Combined with the principle of least privilege, this means that a component will compromise the least possible degree of security—ideally the attacker will only be able to wreak havoc within the bounds of the module’s security scope, never beyond.
Reducing the blast radius of the component, and consequently the attack surface that it exposes for the overall system.
A security sandbox, you could say.
And a pretty good one at that.
PoLP: The Principle of Least Privilege
Never give someone – or something – more freedom than they need.
More formally,
Every module must be able to access only the information and resources that are necessary for its legitimate purpose. – Wikipedia
This way, if the module misbehaves (or is forced to misbehave, by an entity with malicious intent—a hacker, in English), the potential harm it can cause is minimized; without any preventive “action” being taken, and even before the “breach” is identified!
It never gets old
While the principle was initially brought up in the context of legacy systems, it is even more so applicable for “modern” architectures; SOA (well, maybe not so “modern”), microservices, and FaaS (serverless functions, hence serverless security) as well.
The concept is pretty simple: use the underlying access control mechanisms to restrict the permissions available for your “unit of execution”; may it be a simple HTTP server/proxy, web service backend, microservice, container, or serverless function.
Meanwhile, in the land of no servers…
With increased worldwide adoption of serverless technologies, the significance of serverless security, and the value of our PoLP, is becoming more obvious than ever.
Server-less = effort-less
Not having to provision and manage the server (environment) means that serverless devops can proceed at an insanely rapid pace. With CI/CD in place, it’s just a matter of code, commit and push; everything would be up and running within minutes, if not seconds. No SSH logins, file uploads, config syncs, service restarts, routing shifts, or any of the other pesky devops chores associated with a traditional deployment.
“Let’s fix the permissions later.”
Alas, that’s a common thing to hear among those “ops-free” devs (like myself). You’re in a haste to push the latest updates to staging, and the “easy path” to avoid a plethora of “permission denied” errors is to relax the permissions on your FaaS entity (AWS Lambda, Azure Function, whatever).
Staging will soon migrate to prod. And so will your “over-permissioned” function.
And it will stay there. Far longer than you think. You will eventually shift your traffic to updated versions, leaving behind the old one untouched; in fear of breaking some other dependent component in case you step on it.
And then come the sands of time, covering the old function from everybody’s memories.
An obsolete function with unpatched dependencies and possibly flawed logic, having full access to your cloud resources.
A serverless time bomb, if there ever was one.

Yes, blast radius; again!
If we adhere to the least privilege principle, right from the staging deployment, it would greatly reduce the blast radius: by limiting what the function is allowed to do, we automatically limit the “extent of exploitation” upon the rest of the system if its control ever falls into the wrong hands.
Nailing serverless security: on public cloud platforms
These things are easier said than done.
At the moment, among the leaders of public-cloud FaaS technology, only AWS has a sufficiently flexible serverless security model. GCP automatically assigns a default project-level Cloud Platform service account to all its functions in a given project, meaning that all your functions will be in one basket in terms of security and access control. Azure’s IAM model looks more promising, but it still lacks the cool stuff like automatic role-based runtime credential assignments available in both AWS and GCP.
AWS has applied its own IAM role-based permissions model for its Lambda functions, granting users the flexibility to define a custom IAM role—with fully customizable permissions—for every single Lambda function if so desired. It has an impressive array of predefined roles that you can extend upon, and has well-defined strategies for scoping permission to resource or principal categories, merging rules that refer to the same set of resources or operations, and so forth.
This whole hierarchy finally boils down to a set of permissions, each of which takes a rather straightforward format:
{
"Effect": "Allow|Deny",
"Action": "API operation matcher (pattern), or array of them",
"Resource": "entity matcher (pattern), or array of them"
}In English, this simply means:
Allow (or deny) an entity (user, EC2 instance, lambda; whatever) that possesses this permission, to perform the matching API operation(s) against the matching resource(s).
(There are non-mandatory fields Principal and Condition as well, but we’ll skip them here for the sake of brevity.)
Okay, okay! Time for some examples.
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-awesome-bucket/*"
}This allows the assignee to put an object (s3:PutObject) into the bucket named my-awesome-bucket.
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::my-awesome-*"
}This is similar, but allows the put to be performed on any bucket whose name begins with my-awesome-.
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
}This allows the assignee to do any S3 operation (get/put object, delete object, or even delete bucket) against any bucket in its owning AWS account.
And now the silver bullet:
{
"Effect": "Allow",
"Action": "*",
"Resource": "*"
}Yup, that one allows oneself to do anything on anything in the AWS account.

Kind of like the AdministratorAccess managed policy.
And if your principal (say, lambda) gets compromised, the attacker effectively has admin access to your AWS account!
A serverless security nightmare. Needless to say.
To be avoided at all cost.
Period.
In that sense, the best option would be a series of permissions of the first kind; ones that are least permissive (most restricrive) and cover a narrow, well-defined scope.
How hard can that be?
The caveat is that you have to do this for every single operation within that computation unit—say lambda. Every single one.
And it gets worse when you need to configure event sources for triggering those units.
Say, for an API Gateway-triggered lambda, where the API Gateway service must be granted permission to invoke your lambda in the scope of a specific APIG endpoint (in CloudFormation syntax):
{
"Type": "AWS::Lambda::Permission",
"Properties": {
"Action": "lambda:InvokeFunction",
"FunctionName": {
"Ref": "LambdaFunction"
},
"SourceArn": {
"Fn::Sub": [
"arn:aws:execute-api:${AWS::Region}:${AWS::AccountId}:${__ApiId__}/*/${__Method__}${__Path__}",
{
"__Method__": "POST",
"__Path__": "/API/resource/path",
"__ApiId__": {
"Ref": "RestApi"
}
}
]
},
"Principal": "apigateway.amazonaws.com"
}
}Or for a Kinesis stream-powered lambda, in which case things get more complicated: the Lambda function requires access to watch and pull from the stream, while the Kinesis service also needs permission to trigger the lambda:
"LambdaFunctionExecutionRole": {
"Type": "AWS::IAM::Role",
"Properties": {
"ManagedPolicyArns": [
"arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
],
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"sts:AssumeRole"
],
"Effect": "Allow",
"Principal": {
"Service": [
"lambda.amazonaws.com"
]
}
}
]
},
"Policies": [
{
"PolicyName": "LambdaPolicy",
"PolicyDocument": {
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:GetRecords",
"kinesis:GetShardIterator",
"kinesis:DescribeStream",
"kinesis:ListStreams"
],
"Resource": {
"Fn::GetAtt": [
"KinesisStream",
"Arn"
]
}
}
]
}
}
]
}
},
"LambdaFunctionKinesisTrigger": {
"Type": "AWS::Lambda::EventSourceMapping",
"Properties": {
"BatchSize": 100,
"EventSourceArn": {
"Fn::GetAtt": [
"KinesisStream",
"Arn"
]
},
"StartingPosition": "TRIM_HORIZON",
"FunctionName": {
"Ref": "LambdaFunction"
}
}
},
"KinesisStreamPermission": {
"Type": "AWS::Lambda::Permission",
"Properties": {
"Action": "lambda:InvokeFunction",
"FunctionName": {
"Ref": "LambdaFunction"
},
"SourceArn": {
"Fn::GetAtt": [
"KinesisStream",
"Arn"
]
},
"Principal": "kinesis.amazonaws.com"
}
}So you see, with this granularity, comes great power as well as great responsibility. One missing permission—heck, one mistyped letter—and it’s 403 AccessDeniedException.
No easy way; you just have to track down every AWS resource triggering or accessed by your function, look up the docs, pull out your hair, and come up with the necessary permissions.
But… but… that’s too much work!
Yup, it is. If you’re doing it manually.
But who drives manual these days? :)
Fortunately there are quite a few options, if you’re already into automating stuff:
serverless-puresec-cli: thanks PureSec!
If you’re using the famous Serverless Framework – which means you’re already covered on the trigger permissions front – there’s the serverless-puresec-cli plugin from Puresec.

The plugin can statically analyze your lambda code and generate a least-privilege role. Looks really cool, but the caveat is that you have to run the serverless puresec gen-roles command before every deployment with code changes; I couldn’t yet find a way to run it automatically – during serverless deploy, for example. Worse, it just prints the generated roles into stdout; so you have to manually copy-paste it into serverless.yml, or use some other voodoo to actually inject it into the deployment configuration (hopefully things would improve in the future :))
AWS Chalice: from the Gods
If you’re a Python fan, Chalice is capable of auto-generating permissions for you, natively. Chalice is awesome in many aspects; super-fast deployments, annotation-driven triggers, little or no configurations to take care of, and so forth.

However, despite being a direct hand-down from the AWS gods, it seems to have missed the word “minimal” when it comes to permissions; if you have the code to list the contents of some bucket foo, it will generate permissions for listing content of all buckets in the AWS account ("Resource": "*" instead of "Resource": "arn:aws:s3:::foo/*"), not just the bucket you are interested in. Not cool!
No CLI? go for SLAppForge Sigma
If you’re a beginner, or not that fond of CLI tooling, there’s Sigma from SLAppForge.

Being a fully-fledged browser IDE, Sigma will automatically analyze your code as you compose (type or drag-n-drop) it, and derive the necessary permissions—for the Lambda runtime as well as for the triggers—so you are fully covered. The recently introduced Permission Manager also allows you to modify these auto-generated permissions if you desire; for example, if you are integrating a new AWS service/operation that Sigma doesn’t yet know about.
Plus, with Sigma, you never have to worry about any other configurations; resource configs, trigger mappings, entity interrelations and so forth—the IDE takes care of it all.
The caveat is that Sigma only supports NodeJS at the moment; but Python, Java and other cool languages are on their way!
(Feel free to comment below, if you have other cool serverless security policy generation tools in mind! And no, AWS Policy Generator doesn’t count.)
In closing
Least privilege principle is crucial for serverless security, and software design in general; sooner or later, it will save your day. Lambda’s highly granular IAM permission model is ideal for the PoLP.
Tools like the Puresec CLI plugin, all-in-one Sigma IDE and AWS Chalice can automate security policy generation; making your life easier, and still keeping the PoLP promise.
| Published on Java Code Geeks with permission by Janaka Bandara, partner at our JCG program. See the original article here: Serverless Security: Putting it on Autopilot Opinions expressed by Java Code Geeks contributors are their own. |
