One interesting and promising Open Source project that caught my attention lately is Spline, a data lineage tracking and visualization tool for Apache Spark, maintained at Absa. This project consists of 2 parts: a Scala library that works on the drivers which, by analyzing the Spark execution plans, captures the data lineages and a web application which provides a UI to visualize them.
Spline supports MongoDB and HDFS as storage systems for the data lineages in JSON format. In this post I am referring to MongoDB.
You can start playing with Spline through the Spark shell. Just add the required dependencies to the shell classpath as follows (with reference to the latest 0.3.5 release of this project):
spark-shell --packages "za.co.absa.spline:spline-core:0.3.5,za.co.absa.spline:spline-persistence-mongo:0.3.5,za.co.absa.spline:spline-core-spark-adapter-2.3:0.3.5"
Running the Spark shell with the command above on Ubuntu and some other Linux distro, whether some issue on downloading the Joda Time library (transitive dependency for one of the Spline components) should occur, please delete the .ivy1 and .m2 hidden sub-directories of the directory where the spark-shell command has been executed and then re-run it.
Assuming you have your Mongo server up and running and that you have already created an empty database for Spline, the first thing you need to do in the Spark shell is to specify the persistence factory class to use and then the connection string and the database name:
System.setProperty("spline.persistence.factory", "za.co.absa.spline.persistence.mongo.MongoPersistenceFactory")
System.setProperty("spline.mongodb.url", "mongodb://<username>:<password>@<server_name_or_ip>:<port>")
System.setProperty("spline.mongodb.name", "<database_name>")
You can now enable the Spline data lineage tracking:
import za.co.absa.spline.core.SparkLineageInitializer._
spark.enableLineageTracking()
and then start doing something which involves data:
val employeesJson =
spark.read.json("/home/guglielmo/spark-2.3.2-bin-hadoop2.7/examples/src/main/resources/employees.json")
import spark.implicits._val employeeNames = employeesJson.select(employeesJson("name")) employeeNames.write.parquet("/home/guglielmo/spline/example/employee_names")
Whether the following exception should happen:
com.mongodb.MongoCommandException: Command failed with error 9: 'The 'cursor' option is required, except for aggregate with the explain argument' on server localhost:27017. The full response is { "ok" : 0.0, "errmsg" : "The 'cursor' option is required, except for aggregate with the explain argument", "code" : 9, "codeName" : "FailedToParse" }
then you have to update the MongoDB Java driver dependency to any release 3.6+ (it could be done by simply adding it to the list of packages when running the
spark-shell command).
Starting the Spline web application:
java -jar spline-web-0.3.5-exec-war.jar -Dspline.mongodb.url=mongodb://<username>:<password>@<server_name_or_ip>:<port> -Dspline.mongodb.name=<database_name>?
you can see the captured data lineage in the web UI (the default listening port is 8080):
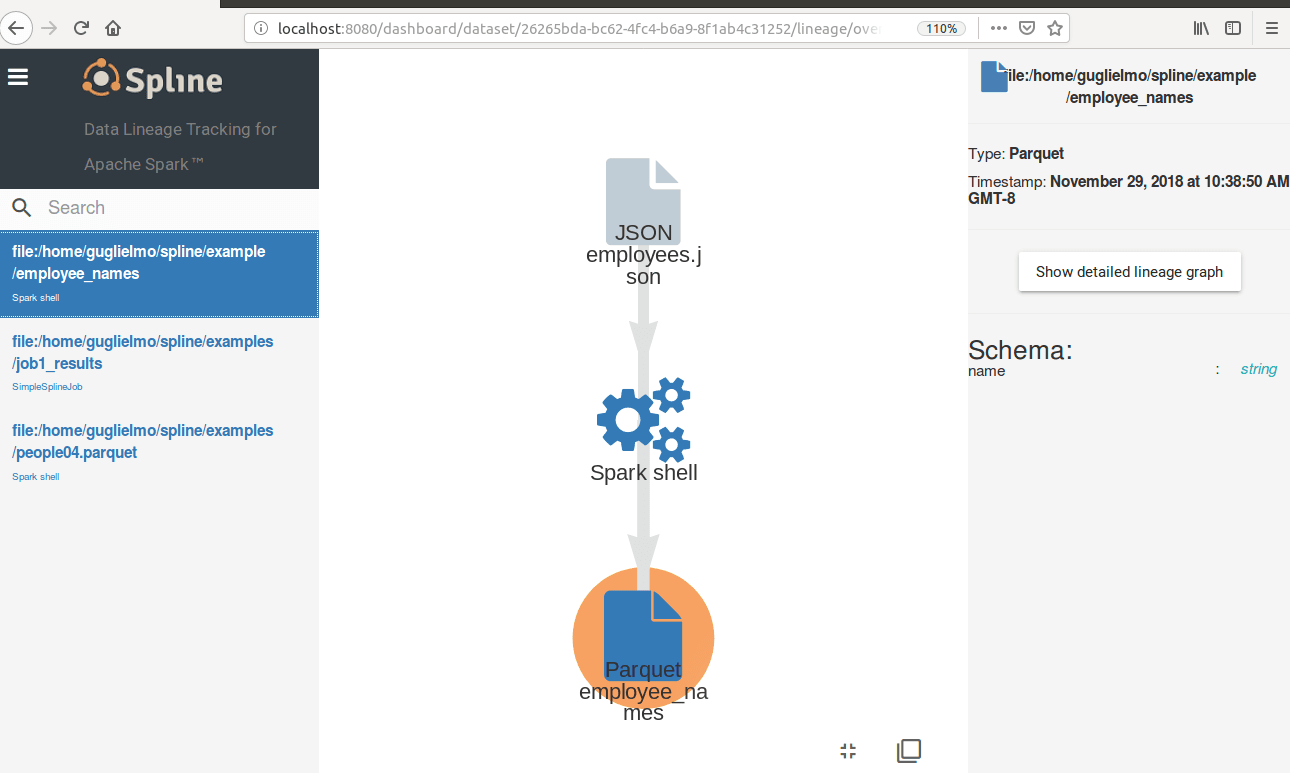
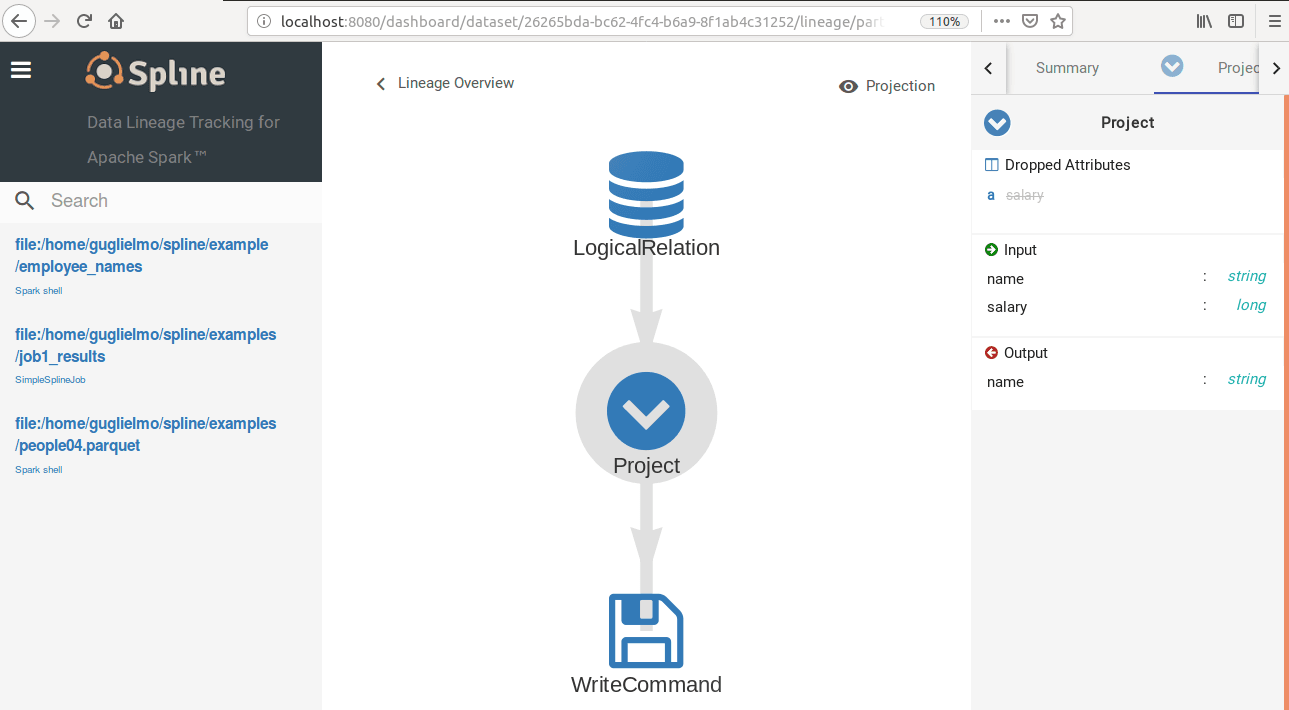
This is just a starter. In part 2 of this series we are going to explore Spline under the hood.
| Published on Java Code Geeks with permission by Guglielmo Iozzia, partner at our JCG program. See the original article here: Exploring the Spline Data Tracker and Visualization tool for Apache Spark (Part 1)
Opinions expressed by Java Code Geeks contributors are their own. |

Trying to steps mentioned by you but I am getting
<console>:24: error: not found: value zafor lineimport za.co.absa.spline.core.SparkLineageInitializer._, any suggestions?Hi Naresh, that error happens when the Spline core dependency isn’t found in the classpath. You can check for confirmation through the Environment tab for the Spark shell you started. It seems that the dependencies import through the –packages option failed for you for some reason.
Same with me: says ” error: not found: value za”
When I type System.getenv(“CLASSPATH”) I only get /usr/lib/jvm/java-8-oracle/lib
Note that the command above says “–packages, when the correct is ” – – packages”. I spent many hours in this until I found out ;)
Thanks Alvaro. For some reason the import of the post to Java Code Geeks shows a single ‘-‘, while the original post in my blog has the correct syntax.
@All the readers: The link to the original post is on the footer of this article.
Hello Alvaro,
For some reason the two dashes were merged into one. It’s now fixed. Sorry for the confusion!
No prob, Eleftheria, and thank you for your reply :)
This is what worked for me:
spark-shell –packages za.co.absa.spline:spline-core:0.3.5,za.co.absa.spline:spline-persistence-mongo:0.3.5,za.co.absa.spline:spline-core-spark-adapter-2.3:0.3.5,org.scala-lang.modules:scala-xml_2.11:1.1.1,com.thoughtworks.paranamer:paranamer:2.8
Hi Alvaro. So you didn’t use the double quotes in the list of packages to import. Could you please share the details of the Linux distribution you tried this? On Ubuntu and Red Hat Server it works with double quotes to me for the Spark shell. In a Spark cluster I don’t use the packages option any way, but I usually add the dependencies through the project descriptor for the specific tool used to build the Spark apps.
Hi Gugliemo, thank you for your reply. I am not using any distribution, just plain spark on ubuntu. I do have lots of problems with dependencies, though, as they never seem to work out. It´d be great having a POM or something in this article :)
Hi,
I am not able to start the Spline-Ui EROOR:Http-404 resource not found
Cmd :java -jar spline-web-0.3.6-exec-war.jar -Dspline.mongodb.url=localhost:27017 -Dspline.mongodb.name=test -httpPort=8677
url:localhost:8677
Please any help is much appreciated.
Thanks for the blog , can you please share the data files : employees.json. i am getting error as following 23:10:20.503 [http-bio-8080-exec-2] ERROR za.co.absa.spline.web.logging.ErrorCode$ – ErrorCode(232e28e4-a31e-407d-b3b9-f616a5c48c70) java.lang.RuntimeException: class za.co.absa.spline.model.op.Write requires value for ‘writeMetrics’ at scala.sys.package$.error(package.scala:27) at salat.DefaultArg.safeValue$lzycompute(Grater.scala:484) at salat.DefaultArg.safeValue(Grater.scala:480) at salat.ConcreteGrater.safeDefault(Grater.scala:435) at salat.ConcreteGrater$$anonfun$7$$anonfun$apply$3.apply(Grater.scala:322) at salat.ConcreteGrater$$anonfun$7$$anonfun$apply$3.apply(Grater.scala:322) at scala.Option.orElse(Option.scala:289) at salat.ConcreteGrater$$anonfun$7.apply(Grater.scala:322) at salat.ConcreteGrater$$anonfun$7.apply(Grater.scala:307) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.immutable.List.map(List.scala:296) at salat.ConcreteGrater.asObject(Grater.scala:307) at salat.ProxyGrater.asObject(ProxyGrater.scala:41) at salat.transformers.in.DBObjectToInContext$class.transform0(Injectors.scala:443) at salat.transformers.in.DBObjectToInContext$class.transform(Injectors.scala:448) at salat.transformers.in.package$$anon$2.salat$transformers$in$TraversableInjector$$super$transform(Injectors.scala:155) at salat.transformers.in.TraversableInjector$class.transformElement(Injectors.scala:482) at salat.transformers.in.package$$anon$2.transformElement(Injectors.scala:155) at salat.transformers.in.TraversableInjector$$anonfun$after$1.apply(Injectors.scala:498) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:234) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike$class.map(TraversableLike.scala:234) at scala.collection.immutable.List.map(List.scala:296) at salat.transformers.in.TraversableInjector$class.after(Injectors.scala:497) at salat.transformers.in.package$$anon$2.after(Injectors.scala:155) at salat.transformers.Transformer$$anonfun$1.apply(Transformer.scala:103) at salat.transformers.Transformer$$anonfun$1.apply(Transformer.scala:101) at scala.Option.flatMap(Option.scala:171) at salat.transformers.Transformer.transform_$bang(Transformer.scala:101) at… Read more »
Hi Rakesh,
The JSON file used for this example is part of the Apache Spark distribution code examples.
Best Regards,
Guglielmo
Is there any documentation on how the data is stored by Apache Spline in case I need to read the data and view in a third party visualization tool
Your writing style and the way you present your content bring clarity and captivate the reader’s attention. Continue the great job.