1. Introduction
With the use of microservices, it has become easy to create stable distributed applications and get rid of many legacy problems. But the use of microservices has introduced a few challenges also and Distributed log management is one of them. As microservices are isolated hence they don’t share database and log files, so it becomes challenging to search, analyse and view log data in real time. This is where ELK stack comes to rescue.
2. ELK
It is a collection of three open source products:
- Elastic search is a JSON Based NoSQL database
- Logstash a log pipeline tool that takes inputs from various sources, executes different conversions and exports the data to various targets (here to elastic search)
- Kibana is a visualization layer that works on top of the elastic search
Refer to the architecture given below:
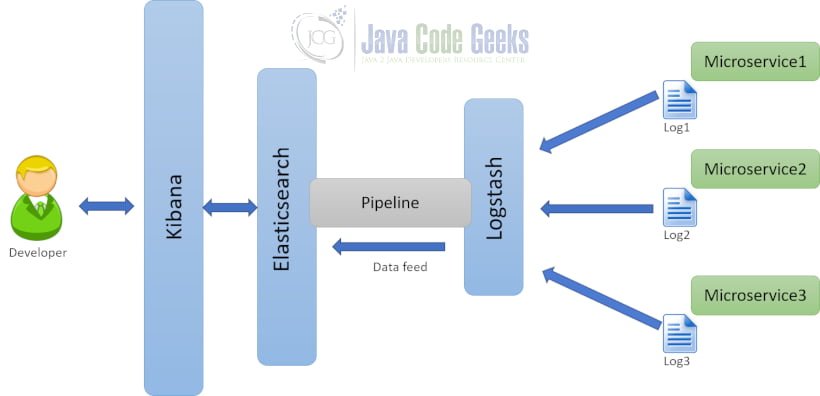
Log stash fetches the logs from the microservices. Fetched logs
are transformed into JSON and fed to the elastic search. Logs present in elastic search are viewed by the developer using the Kibana.
3. Installing ELK
ELK is java based. Before installing ELK it has to be made sure that JAVA_HOME and PATH are set up and
installation is done using JDK 1.8.
3.1 Elasticsearch
- The latest version of Elasticsearch can be downloaded from the download page and it can be
extracted in any folder - It can be executed from the command prompt by using
bin\elasticsearch.bat - By default, it would start at http://localhost:9200
3.2 Kibana
- The latest version of Kibana can be downloaded from the download
page and
it can be extracted into any folder - It can be executed from the command prompt using
bin\kibana.bat - Once started successfully, Kibana will start on default port
5601and
Kibana UI will be available at http://localhost:5601
3.3 Logstash
- The latest version of Logstash can be downloaded
from the download page and it
can be extracted into any folder - Create one file cst_logstash.conf as
per configuration
instructions - It can be executed from the command prompt using
bin/logstashto
-f cst_logstash.conf
start logstash
4. Creating a sample microservice component
It is required to create a microservice so that logstash can
point to the API log. Below listing shows the code for the sample microservice.
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xyz.app</groupId>
<artifactId>ArtDemo1001_Rest_Controller_Full_Deployment_Logging</artifactId>
<version>0.0.1-SNAPSHOT</version>
<!-- Add Spring repositories -->
<!-- (you don't need this if you are using a .RELEASE version) -->
<repositories>
<repository>
<id>spring-snapshots</id>
<url>http://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<url>http://repo.spring.io/milestone</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-snapshots</id>
<url>http://repo.spring.io/snapshot</url>
</pluginRepository>
<pluginRepository>
<id>spring-milestones</id>
<url>http://repo.spring.io/milestone</url>
</pluginRepository>
</pluginRepositories>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.2.RELEASE</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<spring-cloud.version>Dalston.SR3</spring-cloud.version>
</properties>
<!-- Add typical dependencies for a web application -->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<!-- Package as an executable jar -->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
Above code of the pom.xml has configured dependencies that are required by a spring boot based project.
EmployeeDAO.java
package com.xyz.app.dao;
import java.util.Collection;
import java.util.LinkedHashMap;
import java.util.Map;
import org.springframework.stereotype.Repository;
import com.xyz.app.model.Employee;
@Repository
public class EmployeeDAO {
/**
* Map is used to Replace the Database
* */
static public Map<Integer,Employee> mapOfEmloyees =
new LinkedHashMap<Integer,Employee>();
static int count=10004;
static
{
mapOfEmloyees.put(10001, new Employee("Jack",10001,12345.6,1001));
mapOfEmloyees.put(10002, new Employee("Justin",10002,12355.6,1002));
mapOfEmloyees.put(10003, new Employee("Eric",10003,12445.6,1003));
}
/**
* Returns all the Existing Employees
* */
public Collection getAllEmployee(){
return mapOfEmloyees.values();
}
/**Get Employee details using EmployeeId .
* Returns an Employee object response with Data if Employee is Found
* Else returns a null
* */
public Employee getEmployeeDetailsById(int id){
return mapOfEmloyees.get(id);
}
/**Create Employee details.
* Returns auto-generated Id
* */
public Integer addEmployee(Employee employee){
count++;
employee.setEmployeeId(count);
mapOfEmloyees.put(count, employee);
return count;
}
/**Update the Employee details,
* Receives the Employee Object and returns the updated Details
* */
public Employee updateEmployee (Employee employee){
mapOfEmloyees.put(employee.getEmployeeId(), employee);
return employee;
}
/**Delete the Employee details,
* Receives the EmployeeID and returns the deleted employee's Details
* */
public Employee removeEmployee (int id){
Employee emp= mapOfEmloyees.remove(id);
return emp;
}
}
Above code represents the DAO layer of the application. CRUD operations are executed on Map collection containing Employee objects, in order to avoid database dependency and keep the application light.
EmployeeController.java
package com.xyz.app.controller;
import java.util.Collection;
import org.apache.log4j.Logger;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import com.xyz.app.dao.EmployeeDAO;
import com.xyz.app.model.Employee;
@RestController
public class EmployeeController {
@Autowired
private EmployeeDAO employeeDAO;
public static Logger logger = Logger.getLogger(EmployeeController.class);
/** Method is used to get all the employee details and return the same
*/
@RequestMapping(value="emp/controller/getDetails",method=RequestMethod.GET,produces=MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity<Collection> getEmployeeDetails(){
logger.info("From Producer method[getEmployeeDetails] start");
logger.debug("From Producer method[getEmployeeDetails] start");
Collection listEmployee =employeeDAO.getAllEmployee();
logger.debug("From Producer method[getEmployeeDetails] start");
logger.info("From Producer method[getEmployeeDetails] end");
return new ResponseEntity<Collection>(listEmployee, HttpStatus.OK);
}
/** Method finds an employee using employeeId and returns the found Employee
If no employee is not existing corresponding to the employeeId,
then null is returned with HttpStatus.INTERNAL_SERVER_ERROR as status
*/
@RequestMapping(value="emp/controller/getDetailsById/{id}",method=RequestMethod.GET,produces=MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity getEmployeeDetailByEmployeeId(@PathVariable("id") int myId){
logger.info("From Producer method[getEmployeeDetailByEmployeeId] start");
Employee employee = employeeDAO.getEmployeeDetailsById(myId);
if(employee!=null)
{
logger.info("From Producer method[getEmployeeDetailByEmployeeId] end");
return new ResponseEntity(employee,HttpStatus.OK);
}
else
{
logger.info("From Producer method[getEmployeeDetailByEmployeeId] end");
return new ResponseEntity(HttpStatus.NOT_FOUND);
}
}
/** Method creates an employee and returns the auto-generated employeeId */
@RequestMapping(value="/emp/controller/addEmp",
method=RequestMethod.POST,
consumes=MediaType.APPLICATION_JSON_VALUE,
produces=MediaType.TEXT_HTML_VALUE)
public ResponseEntity addEmployee(@RequestBody Employee employee){
logger.info("From Producer method[addEmployee] start");
logger.debug("From Producer method[addEmployee] start");
int empId= employeeDAO.addEmployee(employee);
logger.debug("From Producer method[addEmployee] start");
logger.info("From Producer method[addEmployee] end");
return new ResponseEntity("Employee added successfully with id:"+empId,HttpStatus.CREATED);
}
/** Method updates an employee and returns the updated Employee
If Employee to be updated is not existing, then null is returned with
HttpStatus.INTERNAL_SERVER_ERROR as status
*/
@RequestMapping(value="/emp/controller/updateEmp",
method=RequestMethod.PUT,
consumes=MediaType.APPLICATION_JSON_VALUE,
produces=MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity updateEmployee(@RequestBody Employee employee){
logger.info("From Producer method[updateEmployee] start");
if(employeeDAO.getEmployeeDetailsById(employee.getEmployeeId())==null){
Employee employee2=null;
return new ResponseEntity(employee2,HttpStatus.INTERNAL_SERVER_ERROR);
}
System.out.println(employee);
employeeDAO.updateEmployee(employee);
logger.info("From Producer method[updateEmployee] end");
return new ResponseEntity(employee,HttpStatus.OK);
}
/** Method deletes an employee using employeeId and returns the deleted Employee
If Employee to be deleted is not existing, then null is returned with
HttpStatus.INTERNAL_SERVER_ERROR as status
*/
@RequestMapping(value="/emp/controller/deleteEmp/{id}",
method=RequestMethod.DELETE,
produces=MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity deleteEmployee(@PathVariable("id") int myId){
logger.info("From Producer method[deleteEmployee] start");
if(employeeDAO.getEmployeeDetailsById(myId)==null){
Employee employee2=null;
return new ResponseEntity(employee2,HttpStatus.INTERNAL_SERVER_ERROR);
}
Employee employee = employeeDAO.removeEmployee(myId);
System.out.println("Removed: "+employee);
logger.info("From Producer method[deleteEmployee] end");
return new ResponseEntity(employee,HttpStatus.OK);
}
}
Above code represents the controller layer of the application with the request handlers. Request handlers invoke the DAO layer functions and perform the CRUD operations.
application.properties
server.port = 8090 logging.level.com.xyz.app.controller.EmployeeController=DEBUG #name of the log file to be created #same file will be given as input to logstash logging.file=app.log spring.application.name = producer
Above code represents the properties configured for a spring boot based application.
5. Logstash configuration
As discussed in section 3.3 it is required to create a configuration file for logstash. This configuration file will be used by logstash to take input from the microservice logs. Logs are transformed into JSON and fed to elasticsearch.
cst_logstash.conf
input {
file {
# If more than one log files from different microservices have to be tracked then a comma-separated list of log files can
# be provided
path => ["PATH-TO-UPDATE/app.log"]
codec => multiline {
pattern => "^%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}.*"
negate => "true"
what => "previous"
}
}
}
output {
stdout {
codec => rubydebug
}
# Sending properly parsed log events to elasticsearch
elasticsearch {
hosts => ["localhost:9200"]
}
}
The above logstash configuration file listens to
the log file and pushes log messages to elastic search.
Note: Change the log path as per to your setup.
6. Execution and Output
6.1 Executing microservice for logs
Spring Boot application can be deployed using clean install spring-boot:run and following
URL can be hit from a browser or postman client: http://localhost:8090/emp/controller/getDetails. This will hit the microservice and produce logs on the microservice’s side. These logs will be read by logstash and pushed to elastic search and further, these logs can be viewed using Kibana using next steps.
6.2 Steps to view output on Kibana
- Configure the index in
the management console. Use index value aslogstash-*as a default
configuration. Open the link: http://localhost:5601/app/kibana#/management/kibana/index?_g=() and it will display
the screen as shown below:
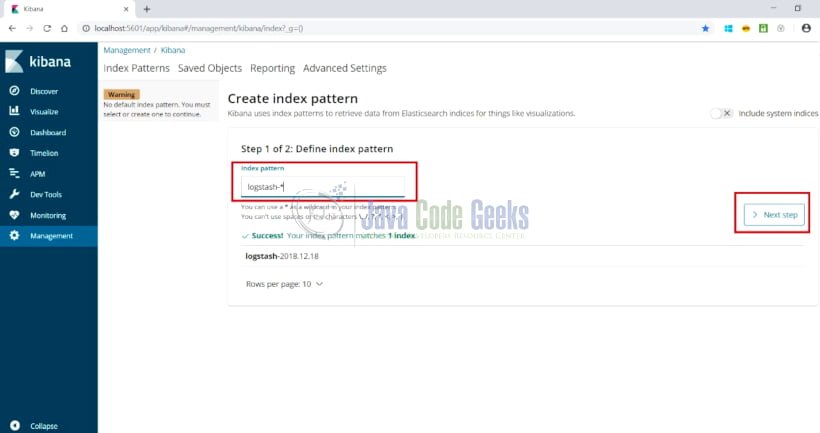
- Click on the Next Step and
the following screen is displayed
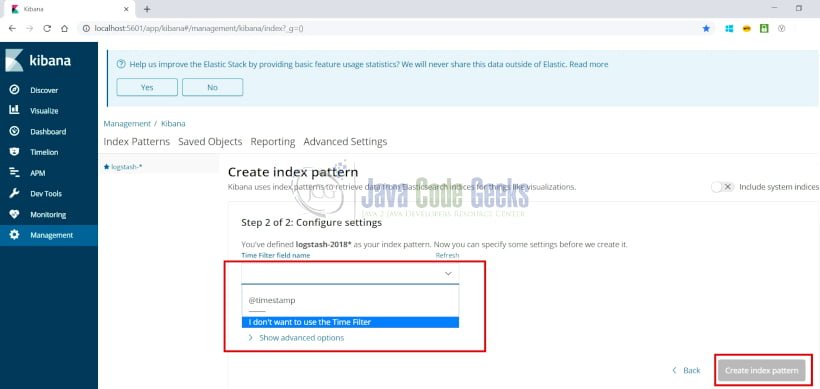
Select the option as highlighted above and click on “Create index pattern”
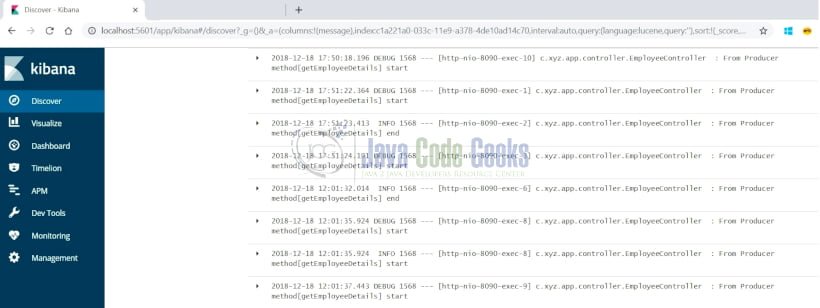
- On selecting Discover option from the left side menu, the page is displayed as shown below:
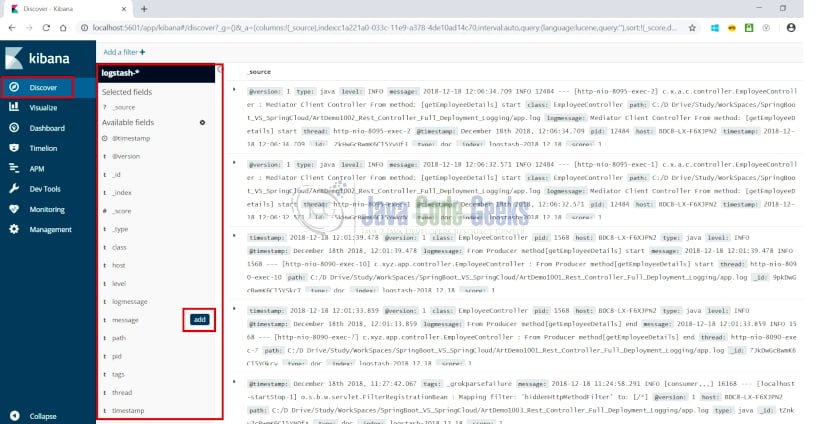
- Logs can be visualized and filtered based upon the properties highlighted above. Upon hovering on any of the properties, “add” button for the property is displayed. Here on selecting the message property view is displayed as shown below:
7. References
-
https://logz.io/learn/complete-guide-elk-stack/
- https://howtodoinjava.com/microservices/elk-stack-tutorial-example/
- https://dzone.com/articles/logging-with-elastic-stack
8. Download the Eclipse Project
You can download the full source code for this example here: microservice
