This series is about the Kubernetes Spark operator by Radanalytics.io on
OpenShift Origin. It is an Open Source operator to manage
Apache Spark clusters and applications.
In order to deploy the operator on OpenShift Origin, the first time you need to clone the GitHub repository for it:
git clone https://github.com/radanalyticsio/spark-operator.git
Then login to the cluster using the OpenShift command-line
oc:
oc login -u <username>:<password>
Assuming, like in the OpenShift Origin environments me and my teams used to work, that developers don’t have permissions to create CRDs, you need to use Config Maps, so you have to create the operator using the
operator-com.yaml file provided in the cloned repo:
oc apply -f manifest/operator-cm.yaml
The output of the command above should be like the following:
serviceaccount/spark-operator created
role.rbac.authorization.k8s.io/edit-resources created
rolebinding.rbac.authorization.k8s.io/spark-operator-edit-resources created
deployment.apps/spark-operator created
Once the operator has been successfully created, you can try to create your first cluster. Select the specific project you want to use:
oc project <project_name>
and then create a small Spark cluster (1 master and 2 workers) using the example file for ConfigMaps available in the cloned repo:
oc apply -f examples/cluster-cm.yaml
Here’s the content of that file:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-spark-cluster
labels:
radanalytics.io/kind: SparkCluster
data:
config: |-
worker:
instances: "2"
master:
instances: "1"
The output of the above command is:
configmap/my-spark-cluster created
After the successful creation of the cluster, looking at the OpenShift web UI, the situation should be:
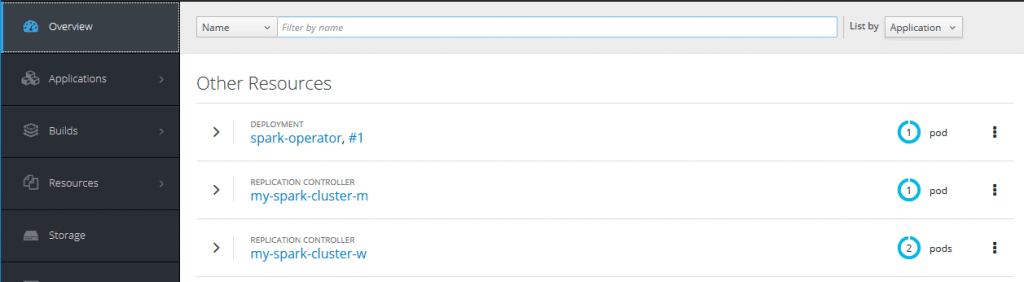
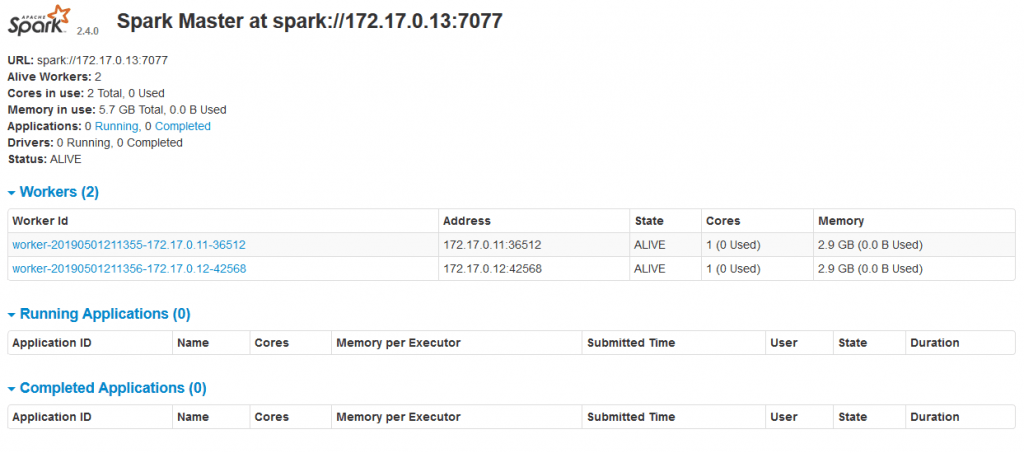
To access the Spark Web UI, you need to create a route for it. It is possible to do so through the OpenShift Origin UI by selecting the Spark service and then clicking on the
route link. Once the route has been created, the Spark web UI for the master (see figure below) and the workers would be accessible from outside OpenShift.
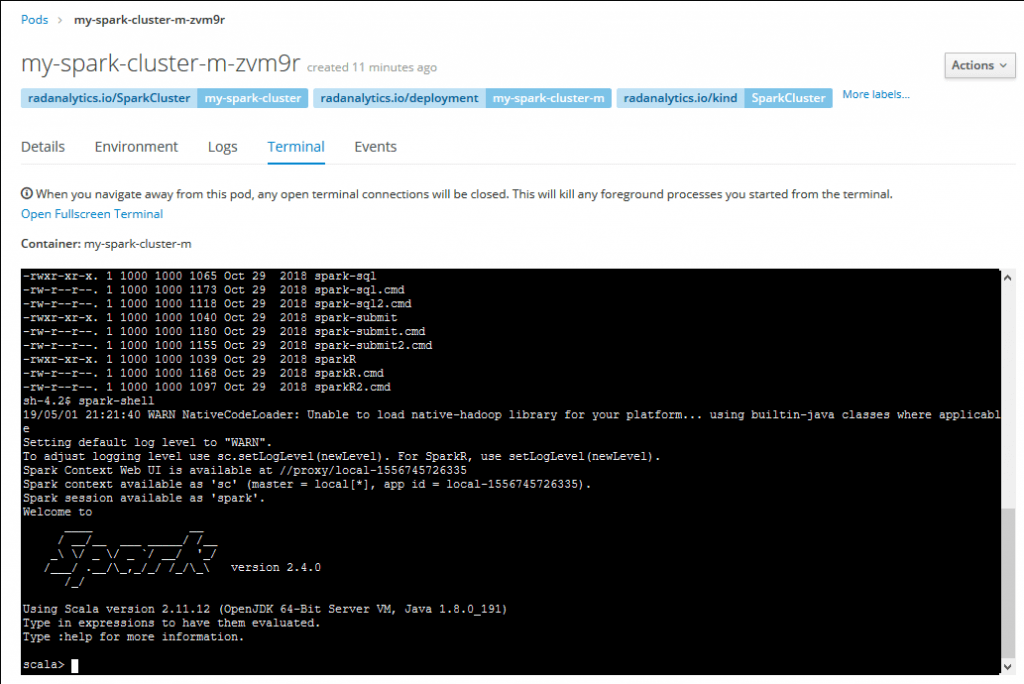
You can now use the Spark cluster. You could start testing it by entering the master pod console, starting a Scala Spark shell there and executing some code:
In the second part of this series we are going to explore the implementation and configuration details for the Spark operator before moving to the Spark applications management.
Published on Java Code Geeks with permission by Guglielmo Iozzia, partner at our JCG program. See the original article here: The Kubernetes Spark operator in OpenShift Origin (Part 1) Opinions expressed by Java Code Geeks contributors are their own. |
