Pattern recognition in data is a common challenge in computational problems. One such pattern involves identifying “hills” and “valleys” in a sequence of numbers. These patterns appear in many real-world applications, such as analyzing elevation data, stock market trends, and signal processing. This article explains how to count the number of hills and valleys in an array of integers using Java.
1. Problem Statement
Given an array of integers, we want to identify and count the “hills” and “valleys.” A hill is defined as a peak surrounded by lower values on both sides, while a valley is a dip surrounded by higher values on both sides. Consecutive duplicate values should be treated as a single plateau when identifying hills or valleys
1.1 Example Input and Output for Counting Hills and Valleys
Given an array of integers, such as [2, 4, 4, 1, 3, 3, 5], the goal is to determine the number of hills and valleys in the array. A hill is a peak surrounded by lower values, while a valley is a dip surrounded by higher values. For example, in the array [2, 4, 4, 1, 3, 3, 5], there is one hill at index 1 (value 4, surrounded by 2 and 1) and one valley at index 3 (value 1, surrounded by 4 and 3).
1.2 Algorithm Overview
- Normalize the Array: Ignore consecutive duplicates to simplify the problem. For example,
[2, 4, 4, 1, 3, 3, 5]becomes[2, 4, 1, 3, 5]. - Traverse the Array: Check each element (excluding the first and last) to determine if it is a hill or a valley.
- Count Hills and Valleys:
- A hill occurs when
arr[i] > arr[i-1]andarr[i] > arr[i+1]. - A valley occurs when
arr[i] < arr[i-1]andarr[i] < arr[i+1].
- A hill occurs when
2. Java Implementation
In this section, we will provide a detailed Java implementation to count hills and valleys in an array of integers. The approach focuses on simplicity and efficiency, making it suitable for both beginners and experienced developers. The implementation involves two primary steps: normalizing the array to remove consecutive duplicates and iterating through the normalized array to identify hills and valleys.
We will also include a main method to test the functionality of our program with sample input arrays. The code is designed to be modular, so you can easily reuse or extend it for similar problems involving array patterns or sequence analysis.
Below is the full Java program:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public class HillValleyCounter { public static int[] countHillsAndValleys(int[] arr) { // Step 1: Normalize the array by removing consecutive duplicates List<Integer> normalizedList = new ArrayList<>(); normalizedList.add(arr[0]); for (int i = 1; i < arr.length; i++) { if (arr[i] != arr[i - 1]) { normalizedList.add(arr[i]); } } int[] normalized = normalizedList.stream().mapToInt(Integer::intValue).toArray(); // Step 2: Count hills and valleys int hills = 0, valleys = 0; for (int i = 1; i < normalized.length - 1; i++) { if (normalized[i] > normalized[i - 1] && normalized[i] > normalized[i + 1]) { hills++; // Hill detected } else if (normalized[i] < normalized[i - 1] && normalized[i] < normalized[i + 1]) { valleys++; // Valley detected } } return new int[]{hills, valleys}; }} |
The code begins by normalizing the array, where consecutive duplicates are removed using a List, simplifying the process by treating duplicate values as a single entity. Next, the program detects hills and valleys by iterating through the normalized array while skipping the first and last elements. During the iteration, conditions check if an element is greater than or smaller than its neighbours to classify it as a hill or a valley, respectively.
3. Testing
Here are five test cases along with their expected outputs:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 | public static void main(String[] args) { int[] arr1 = {1, 3, 2, 4, 1, 5, 6}; int[] result1 = countHillsAndValleys(arr1); System.out.println("Test Case 1 - Hills: " + result1[0] + ", Valleys: " + result1[1]); int[] arr2 = {5, 4, 3, 2, 1}; int[] result2 = countHillsAndValleys(arr2); System.out.println("Test Case 2 - Hills: " + result2[0] + ", Valleys: " + result2[1]); int[] arr3 = {2, 1, 3, 2, 4, 1}; int[] result3 = countHillsAndValleys(arr3); System.out.println("Test Case 3 - Hills: " + result3[0] + ", Valleys: " + result3[1]); int[] arr4 = {1, 2, 3, 4, 3, 2, 1}; int[] result4 = countHillsAndValleys(arr4); System.out.println("Test Case 4 - Hills: " + result4[0] + ", Valleys: " + result4[1]); int[] arr5 = {2, 4, 4, 1, 3, 3, 5}; int[] result5 = countHillsAndValleys(arr5); System.out.println("Test Case 5 - Hills: " + result5[0] + ", Valleys: " + result5[1]);} |
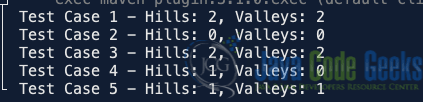
Test Case 1
1 | int[] arr = {1, 3, 2, 4, 1, 5, 6}; |
The expected output is 2 hills and 2 valleys. With these input values, the first hill occurs at index 1 with the value 3, surrounded by 1 and 2. The first valley is at index 2 with the value 2, surrounded by 3 and 4. The second hill is at index 3 with the value 4, surrounded by 2 and 1. Finally, the second valley is at index 4 with the value 1, surrounded by 4 and 5.
Test Case 2
1 | int[] arr = {5, 4, 3, 2, 1}; |
The expected output is 0 hills and 0 valleys. The array is strictly decreasing, so there are no hills or valleys.
Test Case 3
1 | int[] arr = {2, 1, 3, 2, 4, 1}; |
The expected output is 2 hills and 2 valleys. The array {2, 1, 3, 2, 4, 1} has two hills and two valleys because the first hill is at index 2 with the value 3, surrounded by 1 and 2. The first valley is at index 1 with the value 1, surrounded by 2 and 3. The second hill is at index 4 with the value 4, surrounded by 2 and 1, and the second valley is at index 3 with the value 2, surrounded by 3 and 4.
Test Case 4
1 | int[] arr = {1, 2, 3, 4, 3, 2, 1}; |
The expected output is 1 hill and 0 valleys. The array {1, 2, 3, 4, 3, 2, 1} has one hill and no valleys. The hill is at index 3 with the value 4, which is surrounded by 3 and 3. There are no valleys in the array, as no element is lower than both of its neighbours.
Test Case 5
1 | int[] arr5 = {2, 4, 4, 1, 3, 3, 5}; |
The expected output is 1 hill and 1 valley. For the array {2, 4, 4, 1, 3, 3, 5}, after normalizing to remove consecutive duplicates, we get the array {2, 4, 1, 3, 5}. In this normalized array, there is one hill at index 1 with the value 4, surrounded by 2 and 1. There is also one valley at index 2 with the value 1, surrounded by 4 and 3. Thus, the array has 1 hill and 1 valley.
4. Time Complexity
The time complexity of the solution can be broken into two parts. First, the normalization step, which removes consecutive duplicates from the array, operates in O(n), where n is the length of the input array. Second, the hill and valley counting step iterates through the normalized array, which has a length m (m≤n), and operates in O(m). Since m is at most equal to n, the overall time complexity of the solution is O(n).
5. Conclusion
This Java program provides an efficient and clear way to count hills and valleys in an array. By normalizing the array and using straightforward conditions, the solution ensures accurate results with minimal complexity. This approach can be adapted to various applications requiring pattern recognition in sequences.
6. Download the Source Code
This article explores counting hills and valleys in a Java Array.
You can download the full source code of this example here: Java array count hills valleys
