The Spring AI MongoDB RAG Tutorial offers a comprehensive guide to building a Retrieval-Augmented Generation (RAG) application using Spring Boot, MongoDB Atlas, and an AI language model. This tutorial takes you through the essential steps of embedding textual data into high-dimensional vectors, storing these vectors in MongoDB, and leveraging them for efficient similarity searches. It also covers setting up the project environment, configuring necessary dependencies, and creating REST endpoints for document processing and query handling.
By following this tutorial, you’ll learn how to implement a seamless workflow where user queries are transformed into vectors, matched against stored document vectors in MongoDB, and processed by an AI model to generate contextually enriched responses. The integration of these technologies ensures that your RAG application delivers precise, relevant, and dynamic answers, enhancing user experience and interaction. This hands-on approach not only equips you with the technical skills to build a robust RAG system but also demonstrates the practical application of AI in real-world scenarios.
1. Introduction
Building a Retrieval-Augmented Generation (RAG) app using MongoDB and Spring AI represents an exciting intersection of advanced natural language processing and scalable database management. The process begins with the creation of a document embedding system, where textual data is transformed into high-dimensional vectors that encapsulate the semantic meaning of the content. These embeddings are then stored in a MongoDB Atlas vector store, which allows for efficient retrieval based on the similarity of these vector representations.
When a user query is received, the RAG model uses an embedding model to convert the query into a vector. This vector is compared against the stored vectors in MongoDB to retrieve the most relevant documents. These documents provide the necessary context for the query, which is then passed to a large language model (LLM) within the Spring AI framework. The LLM uses this contextual information to generate responses that are both accurate and contextually relevant.
This setup ensures that the application can handle real-time queries effectively, providing users with precise and up-to-date information. It combines the strengths of MongoDB’s robust data management capabilities with the advanced processing power of Spring AI, resulting in a powerful tool for applications requiring high levels of accuracy and contextual understanding. By integrating these technologies, developers can create responsive, intelligent systems that significantly enhance user interaction and satisfaction.
Now let us look at how to build RAG applications using Spring AI and OpenAI-based LLMs.
2. RAG Applications
Retrieval-augmented generation (RAG) applications represent a cutting-edge approach in artificial intelligence, combining the strengths of retrieval-based systems and generative models. This hybrid method enhances the capability of AI to generate contextually relevant and accurate responses by leveraging a vast repository of pre-existing information. A typical RAG application begins with a retrieval mechanism that scans a database or a collection of documents to find information relevant to a user’s query. This retrieved content provides a rich contextual foundation upon which a generative model can build, ensuring the responses are coherent and grounded in accurate data.
One of the primary advantages of RAG applications is their ability to handle complex queries with nuanced contexts, making them ideal for customer support, content generation, and knowledge management systems. By retrieving pertinent data, these applications can generate responses that are more precise and informative compared to standalone generative models. This approach also mitigates the risk of generating hallucinated or incorrect information, as the generative model relies on real-world data to inform its outputs.
Moreover, RAG applications are highly adaptable and can be tailored to various domains, from legal and medical fields to customer service and education. They offer a dynamic and interactive user experience, where responses are continually refined based on the latest and most relevant information available. This ensures that users receive up-to-date and context-aware answers, enhancing their overall satisfaction and trust in the system.
Overall, RAG applications mark a significant advancement in AI technology, bridging the gap between retrieval-based and generative approaches. By synergizing these methods, they provide a powerful tool for delivering accurate, relevant, and contextually enriched responses, setting a new standard for intelligent systems.
2.1 Java Code for SpringAI Controller
Let us look at the java code for the implementation:
package org.javacodegeeks.rag.controller;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.document.Document;
import org.javacodegeeks.rag.model.RAGRequest;
import org.javacodegeeks.rag.service.RAGService;
@RestController
@RequestMapping("/rag")
public class RAGController {
@Autowired
private RAGService ragService;
private final ChatModel chatModel;
private final String PROMPT_BLUEPRINT = """
Answer the query strictly referring the provided context:
{context}
Query:
{query}
In case you don't have any answer from the context provided, just say:
I'm sorry I don't have the information you are looking for.
""";
@Autowired
public RAGController(OpenAiChatModel chatModel) {
this.chatModel = chatModel;
}
@PostMapping("/new_request")
public String addDocuments(@RequestBody List documents) {
ragService.addDocuments(documents);
return "Documents added successfully";
}
@GetMapping("/find")
public String searchDocuments(
@RequestParam String query,
@RequestParam int top_k,
@RequestParam double threshold) {
return chatModel.call(createPrompt(query,ragService.searchDocuments(query, top_k, threshold)));
}
@GetMapping("/healthcheck")
public String status() {
return ragService.getStatus();
}
private String createPrompt(String query, List context) {
PromptTemplate promptTemplate = new PromptTemplate(PROMPT_BLUEPRINT);
promptTemplate.add("query", query);
promptTemplate.add("context", context);
return promptTemplate.render();
}
}
You can initialise the SpringAI application for auto wiring the instances.
spring.application.name=springai-mongodb spring.ai.openai.api-key=xxxxxxx spring.ai.openai.chat.options.model=gpt-3.5-turbo spring.ai.vectorstore.mongodb.initialize-schema=true spring.data.mongodb.uri=mongodb://raguser:raguser@localhost:27017/admin spring.data.mongodb.database=rag_store spring.ai.vectorstore.mongodb.indexName=vector_index spring.ai.vectorstore.mongodb.collection-name=rag_store
Now let us look at the RAG service which is called by the RAG Controller.
package org.javacodegeeks.rag.service;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.javacodegeeks.rag.model.RAGRequest;
import org.javacodegeeks.rag.repository.RAGRepository;
@Service
public class RAGService {
@Autowired
private RAGRepository ragRepository;
public void addDocuments(List documents) {
List docs = documents.stream()
.map(doc -> new Document(doc.getContent(), doc.getMetadata()))
.collect(Collectors.toList());
ragRepository.addDocuments(docs);
}
public List searchDocuments(String query, int topK, double similarityThreshold) {
SearchRequest searchRequest = SearchRequest.query(query)
.withTopK(topK)
.withSimilarityThreshold(similarityThreshold);
List results = ragRepository.searchDocuments(searchRequest);
return results;
}
public String getStatus() {
return "RAG app is working fine";
}
}
The next step is to look at the RAG Repository interface first.
package org.javacodegeeks.rag.repository;
import java.util.List;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
public interface RAGRepository {
void addDocuments(List documents);
List searchDocuments(SearchRequest searchRequest);
}
To implement we need to have MongoDB Atlas configured. We will be using docker to pull the MongoDB Atlas images.
3. Spring AI MongoDB RAG – MongoDB Atlas Vector Search
MongoDB Atlas Vector Search is an advanced feature that enhances the capabilities of MongoDB Atlas by enabling efficient similarity searches on high-dimensional vector data. This technology is particularly useful in applications that require the handling and retrieval of complex, unstructured data such as text, images, and multimedia. By transforming these data types into vectors, MongoDB Atlas Vector Search allows for the comparison and retrieval of data based on similarity measures, rather than exact matches.
The process begins with the embedding of data into high-dimensional vectors using specialized models that capture the semantic essence of the data. These vectors are then stored in MongoDB Atlas, leveraging its robust and scalable database infrastructure. When a query is made, the system converts the input into a vector and performs a similarity search against the stored vectors. This allows for the identification of data points that are most similar to the query, enabling more intuitive and relevant search results.
MongoDB Atlas Vector Search is designed to handle large-scale datasets with high efficiency, making it suitable for various applications such as recommendation systems, personalized content delivery, and fraud detection. By integrating vector search capabilities with MongoDB’s flexible data model and powerful query language, developers can build sophisticated applications that provide enhanced user experiences and more accurate results. This feature represents a significant advancement in the ability to manage and utilize complex data within MongoDB Atlas, opening new possibilities for innovation and data-driven decision-making.
3.1 Docker Setup for Spring AI MongoDB RAG
Let us first look at the docker-compose.yml to pull the docker image. You need to have docker setup done before this step.
version: '3.1'
services:
my-mongodb:
image: mongodb/mongodb-atlas-local:7.0.9
container_name: rag-mongodb
environment:
- MONGODB_INITDB_ROOT_USERNAME=raguser
- MONGODB_INITDB_ROOT_PASSWORD=raguser
ports:
- 27017:27017
You can start pulling the image and run the container for mongodb-atlas-local by using this command
docker-compose up -d
The output for the above commands when executed is shown below:
bhagvanarch@Bhagvans-MacBook-Air mongo-docker % docker-compose up -d [+] Running 1/1 Container rag-mongodb Started
3.2 Spring AI MongoDB RAG – MongoDB Atlas Repository
Now let us implement the RAGRepository and the code below is for RAGRepositoryImpl
package org.javacodegeeks.rag.repository;
import java.util.List;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
@Repository
public class RAGRepositoryImpl implements RAGRepository {
@Autowired
private VectorStore vectorStore;
@Override
public void addDocuments(List documents) {
vectorStore.add(documents);
}
@Override
public List searchDocuments(SearchRequest searchRequest) {
return vectorStore.similaritySearch(searchRequest);
}
}
4. Spring AI MongoDB RAG – Dependencies and Configuration
Building a Retrieval-Augmented Generation (RAG) app with MongoDB and Spring AI involves several critical dependencies and meticulous configuration to ensure seamless operation. The project setup begins by incorporating essential dependencies into your project. This includes MongoDB Java drivers to facilitate database interactions, Spring Boot for creating a robust backend framework, and AI libraries for tasks like embedding and natural language processing. Choosing the right versions of these libraries is crucial for ensuring compatibility and optimal performance.
The next step is configuring the MongoDB database within the Spring Boot application. This involves setting up connection parameters, such as the database URL, username, and password, in the application properties file. Additionally, configuring the MongoDB Atlas to handle the storage and retrieval of high-dimensional vector data is essential. Proper setup ensures efficient and accurate similarity searches, which are vital for the RAG model’s retrieval mechanism.
For the AI component, you need to integrate embedding models and large language models within the Spring framework. This involves loading pre-trained models and ensuring they are correctly linked to your data retrieval system. Configuring API endpoints and services in Spring Boot to handle queries, process embeddings, and generate responses is also necessary. This setup allows the RAG app to manage requests effectively, delivering context-aware responses based on retrieved data.
Overall, setting up a RAG app using MongoDB and Spring AI demands careful attention to dependencies and configuration. By ensuring all components are correctly integrated and configured, you create a powerful application capable of providing advanced, contextually enriched responses, leveraging the strengths of both MongoDB and Spring AI.
The vectorstore for MongodB and MongoDB configuration is setup in the application.properties shown below:
Let us look at the java code for the implementation:
spring.application.name=springai-mongodb spring.ai.openai.api-key=xxxxxxx spring.ai.openai.chat.options.model=gpt-3.5-turbo spring.ai.vectorstore.mongodb.initialize-schema=true spring.data.mongodb.uri=mongodb://raguser:raguser@localhost:27017/admin spring.data.mongodb.database=rag_store spring.ai.vectorstore.mongodb.indexName=vector_index spring.ai.vectorstore.mongodb.collection-name=rag_store
You can compile and execute the above code with the following commands:
mvn clean mvn package mvn spring-boot:run
The output for the above commands when executed is shown below:
bhagvanarch@Bhagvans-MacBook-Air rag_springai_mongodb % mvn spring-boot:run
[INFO] Scanning for projects...
[INFO]
[INFO] ----------------------------------------
[INFO] Building rag-springai-mongodb 0.0.1-SNAPSHOT
[INFO] from pom.xml
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
[INFO] >>> spring-boot:3.3.0:run (default-cli) > test-compile @ springai-mongodb >>>
[INFO]
[INFO] --- resources:3.3.1:resources (default-resources) @ springai-mongodb ---
[INFO] Copying 1 resource from src/main/resources to target/classes
[INFO] Copying 0 resource from src/main/resources to target/classes
[INFO]
[INFO] --- compiler:3.13.0:compile (default-compile) @ springai-mongodb ---
[INFO] Recompiling the module because of changed source code.
[INFO] Compiling 7 source files with javac [debug parameters release 17] to target/classes
[INFO]
[INFO] --- resources:3.3.1:testResources (default-testResources) @ springai-mongodb ---
[INFO] skip non existing resourceDirectory /Users/bhagvanarch/kazdesk/javacodegeeks/code/rag_mongodb_atlas_spring_ai/rag_springai_mongodb/src/test/resources
[INFO]
[INFO] --- compiler:3.13.0:testCompile (default-testCompile) @ springai-mongodb ---
[INFO] No sources to compile
[INFO]
[INFO] <<< spring-boot:3.3.0:run (default-cli) < test-compile @ springai-mongodb <<<
[INFO]
[INFO]
[INFO] --- spring-boot:3.3.0:run (default-cli) @ springai-mongodb ---
[INFO] Attaching agents: []
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.3.0)
2024-11-18T22:21:16.925+05:30 INFO 2157 --- [springai-mongodb] [ main] o.j.rag.RAGMongoDBApplication : Starting RAGMongoDBApplication using Java 17.0.13 with PID 2157 (/Users/bhagvanarch/kazdesk/javacodegeeks/code/rag_mongodb_atlas_spring_ai/rag_springai_mongodb/target/classes started by bhagvanarch in /Users/bhagvanarch/kazdesk/javacodegeeks/code/rag_mongodb_atlas_spring_ai/rag_springai_mongodb)
2024-11-18T22:21:16.927+05:30 INFO 2157 --- [springai-mongodb] [ main] o.j.rag.RAGMongoDBApplication : No active profile set, falling back to 1 default profile: "default"
2024-11-18T22:21:17.295+05:30 INFO 2157 --- [springai-mongodb] [ main] .s.d.r.c.RepositoryConfigurationDelegate : Bootstrapping Spring Data MongoDB repositories in DEFAULT mode.
2024-11-18T22:21:17.303+05:30 INFO 2157 --- [springai-mongodb] [ main] .s.d.r.c.RepositoryConfigurationDelegate : Finished Spring Data repository scanning in 6 ms. Found 0 MongoDB repository interfaces.
2024-11-18T22:21:17.464+05:30 INFO 2157 --- [springai-mongodb] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8080 (http)
2024-11-18T22:21:17.470+05:30 INFO 2157 --- [springai-mongodb] [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2024-11-18T22:21:17.470+05:30 INFO 2157 --- [springai-mongodb] [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.24]
2024-11-18T22:21:17.500+05:30 INFO 2157 --- [springai-mongodb] [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2024-11-18T22:21:17.500+05:30 INFO 2157 --- [springai-mongodb] [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 475 ms
2024-11-18T22:21:17.753+05:30 INFO 2157 --- [springai-mongodb] [ main] org.mongodb.driver.client : MongoClient with metadata {"driver": {"name": "mongo-java-driver|sync|spring-boot", "version": "5.0.1"}, "os": {"type": "Darwin", "name": "Mac OS X", "architecture": "aarch64", "version": "14.6.1"}, "platform": "Java/Homebrew/17.0.13+0"} created with settings MongoClientSettings{readPreference=primary, writeConcern=WriteConcern{w=null, wTimeout=null ms, journal=null}, retryWrites=true, retryReads=true, readConcern=ReadConcern{level=null}, credential=MongoCredential{mechanism=null, userName='raguser', source='admin', password=, mechanismProperties=}, transportSettings=null, commandListeners=[], codecRegistry=ProvidersCodecRegistry{codecProviders=[ValueCodecProvider{}, BsonValueCodecProvider{}, DBRefCodecProvider{}, DBObjectCodecProvider{}, DocumentCodecProvider{}, CollectionCodecProvider{}, IterableCodecProvider{}, MapCodecProvider{}, GeoJsonCodecProvider{}, GridFSFileCodecProvider{}, Jsr310CodecProvider{}, JsonObjectCodecProvider{}, BsonCodecProvider{}, EnumCodecProvider{}, com.mongodb.client.model.mql.ExpressionCodecProvider@511da44f, com.mongodb.Jep395RecordCodecProvider@4645679e, com.mongodb.KotlinCodecProvider@3a0b6a]}, loggerSettings=LoggerSettings{maxDocumentLength=1000}, clusterSettings={hosts=[localhost:27017], srvServiceName=mongodb, mode=SINGLE, requiredClusterType=UNKNOWN, requiredReplicaSetName='null', serverSelector='null', clusterListeners='[]', serverSelectionTimeout='30000 ms', localThreshold='15 ms'}, socketSettings=SocketSettings{connectTimeoutMS=10000, readTimeoutMS=0, receiveBufferSize=0, proxySettings=ProxySettings{host=null, port=null, username=null, password=null}}, heartbeatSocketSettings=SocketSettings{connectTimeoutMS=10000, readTimeoutMS=10000, receiveBufferSize=0, proxySettings=ProxySettings{host=null, port=null, username=null, password=null}}, connectionPoolSettings=ConnectionPoolSettings{maxSize=100, minSize=0, maxWaitTimeMS=120000, maxConnectionLifeTimeMS=0, maxConnectionIdleTimeMS=0, maintenanceInitialDelayMS=0, maintenanceFrequencyMS=60000, connectionPoolListeners=[], maxConnecting=2}, serverSettings=ServerSettings{heartbeatFrequencyMS=10000, minHeartbeatFrequencyMS=500, serverListeners='[]', serverMonitorListeners='[]'}, sslSettings=SslSettings{enabled=false, invalidHostNameAllowed=false, context=null}, applicationName='null', compressorList=[], uuidRepresentation=JAVA_LEGACY, serverApi=null, autoEncryptionSettings=null, dnsClient=null, inetAddressResolver=null, contextProvider=null}
2024-11-18T22:21:17.775+05:30 INFO 2157 --- [springai-mongodb] [localhost:27017] org.mongodb.driver.cluster : Monitor thread successfully connected to server with description ServerDescription{address=localhost:27017, type=REPLICA_SET_PRIMARY, state=CONNECTED, ok=true, minWireVersion=0, maxWireVersion=21, maxDocumentSize=16777216, logicalSessionTimeoutMinutes=30, roundTripTimeNanos=15513250, setName='38f6f1511d6f', canonicalAddress=38f6f1511d6f:27017, hosts=[38f6f1511d6f:27017], passives=[], arbiters=[], primary='38f6f1511d6f:27017', tagSet=TagSet{[]}, electionId=7fffffff0000000000000003, setVersion=1, topologyVersion=TopologyVersion{processId=673b63ec15cd145e78912e8b, counter=6}, lastWriteDate=Mon Nov 18 22:21:15 IST 2024, lastUpdateTimeNanos=2522199210208}
2024-11-18T22:21:19.374+05:30 INFO 2157 --- [springai-mongodb] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/'
2024-11-18T22:21:19.380+05:30 INFO 2157 --- [springai-mongodb] [ main] o.j.rag.RAGMongoDBApplication : Started RAGMongoDBApplication in 2.596 seconds (process running for 2.738)
Let us now do the health check. You need to have the postman installed. You can see the screen shot below the output when invoked.
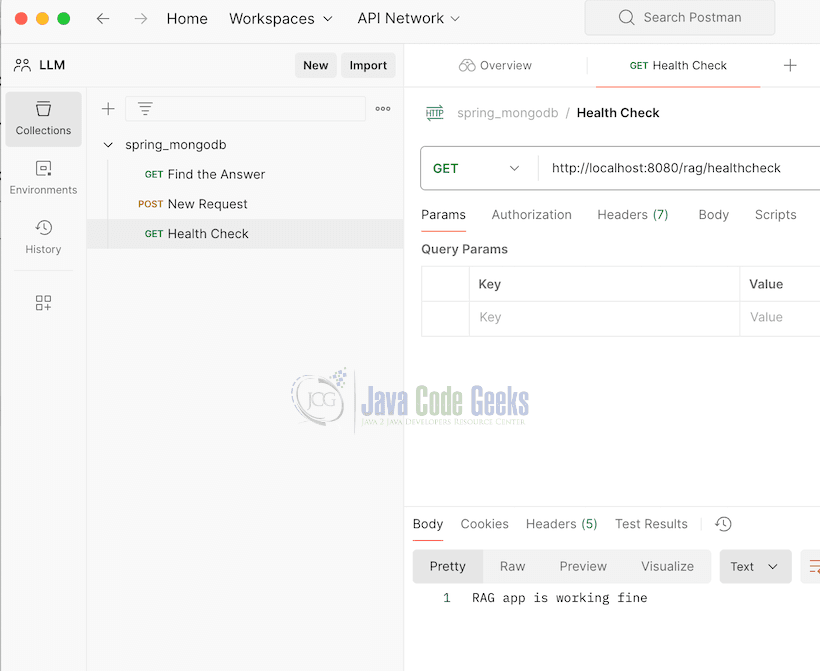
Let us now look at storing documents in the Vector store of MongoDB.
5. Save Documents to the Vector Store
Saving documents to a vector store involves transforming textual data into high-dimensional vector representations, which capture the semantic essence of the content. This process is essential for applications that leverage advanced search and retrieval mechanisms based on similarity. Initially, each document is processed through an embedding model, which converts the text into a dense vector. These vectors are numerical representations that encode the contextual and semantic meaning of the documents, enabling more intuitive and accurate retrieval operations.
Once the documents are embedded, the resulting vectors are stored in a vector store, such as MongoDB Atlas, designed to handle high-dimensional data efficiently. This vector store not only stores the vector representations but also provides mechanisms for similarity searches. When a query is made, it is also converted into a vector, and the vector store searches for the most similar vectors within its database. This retrieval process allows for the identification of documents that are contextually relevant to the query, even if the exact terms used do not match.
The integration of a vector store with your application enhances its ability to perform complex searches, recommendations, and context-aware responses. By leveraging the power of embeddings and efficient storage solutions, developers can build systems that provide highly relevant results, improving user experience and satisfaction. Overall, saving documents to a vector store is a crucial step in creating intelligent applications that understand and process data in a more human-like manner.
We can add documents to the MongoDB Atlas vector store. Let us invoke the new request to add doducments using postman. You can see the screen shot below the output when invoked.
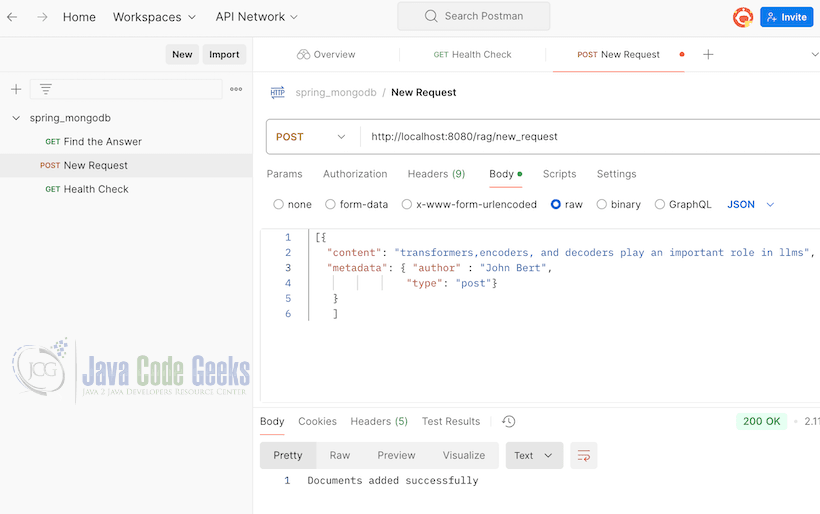
Let us look at Similarity Search using Spring AI, RAG,and LLM.
6. Similarity Search
Similarity search within a Retrieval-Augmented Generation (RAG) app using MongoDB and Spring AI is a sophisticated process that significantly enhances the ability to provide contextually relevant responses. The approach begins with converting both the query and stored documents into high-dimensional vectors using an embedding model. These vectors encapsulate the semantic meaning of the text, allowing for more intuitive and accurate comparisons.
When a user submits a query, the system translates it into a vector and performs a similarity search against the vectors stored in MongoDB. This search process identifies the documents that are most semantically similar to the query, retrieving those that provide the richest context. MongoDB’s efficient handling of high-dimensional data ensures that these similarity searches are conducted swiftly and accurately.
The retrieved documents are then fed into a large language model (LLM) within the Spring AI framework. This model uses the contextual information from the retrieved documents to generate a response that is both accurate and contextually enriched. By leveraging the power of similarity search, the RAG app ensures that responses are not only relevant but also highly detailed and nuanced, meeting the specific needs of the user query.
Overall, similarity search in a RAG app using MongoDB and Spring AI combines advanced data retrieval with powerful generative capabilities, creating a seamless and intelligent user experience. This integration allows for real-time, context-aware responses that enhance user interaction and satisfaction, making it a highly effective tool for various applications requiring precise information retrieval and response generation.
We can find the answer for the query using Spring AI, RAG through MongoDB Atlas vector store, and LLM. Let us invoke the find answer using postman. You can see the screen shot below the output when invoked.
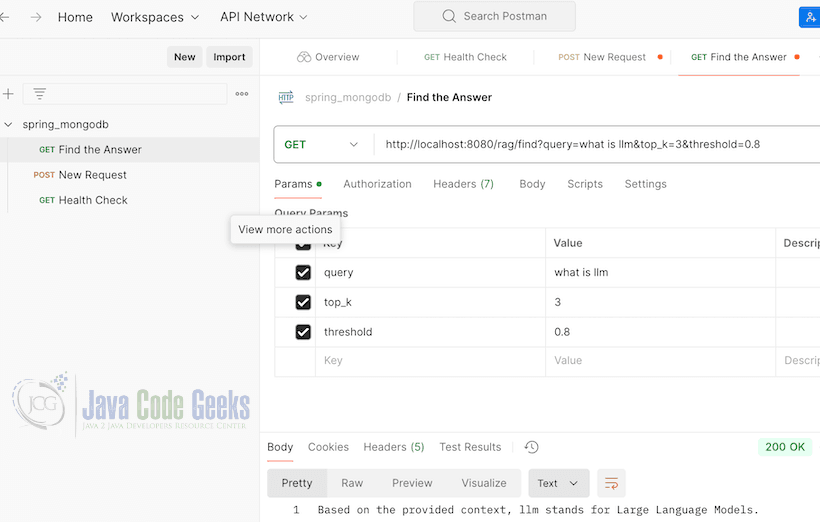
Now let us look at the Prompts and the Endpoint associated with Open AI LLM.
7. Prompt Endpoint
Creating a Prompt Endpoint in a Retrieval-Augmented Generation (RAG) app using MongoDB and Spring AI involves setting up a sophisticated mechanism to handle real-time queries and generate contextually enriched responses. The process starts by integrating MongoDB as a robust database solution capable of storing and retrieving vectorized representations of documents. These vectors, derived from an embedding model, capture the semantic content of the documents, facilitating efficient similarity searches.
In the Spring AI framework, a prompt endpoint is established to receive user queries. When a query is submitted, the system first converts it into a high-dimensional vector using an embedding model. This vector is then compared against the pre-stored vectors in MongoDB to retrieve the most relevant documents based on their semantic similarity. The retrieved documents provide the necessary context for the next stage.
The context-rich documents are then fed into a large language model (LLM) within the Spring AI framework. This LLM utilizes the contextual information to generate a response that is both accurate and contextually relevant to the user’s query. The prompt endpoint thus serves as the interface between the user and the RAG system, ensuring that queries are handled efficiently and responses are generated dynamically.
By leveraging the strengths of MongoDB’s data management capabilities and Spring AI’s advanced processing power, the prompt endpoint in a RAG app facilitates an interactive and intelligent user experience. It allows the system to deliver precise and relevant answers in real-time, enhancing the overall effectiveness and user satisfaction of the application. This setup is ideal for applications requiring high degrees of contextual understanding and accurate information retrieval.
You can see the prompt which we used to invoke the LLM for gpt-3.5-turbo endpoint on OpenAI.
private final String PROMPT_BLUEPRINT = """
Answer the query strictly referring the provided context:
{context}
Query:
{query}
In case you don't have any answer from the context provided, just say:
I'm sorry I don't have the information you are looking for.
""";
private String createPrompt(String query, List context) {
PromptTemplate promptTemplate = new PromptTemplate(PROMPT_BLUEPRINT);
promptTemplate.add("query", query);
promptTemplate.add("context", context);
return promptTemplate.render();
}
The endpoint is configured in application.properties. It is shown below:
spring.application.name=springai-mongodb spring.ai.openai.api-key=xxxxxxx spring.ai.openai.chat.options.model=gpt-3.5-turbo spring.ai.vectorstore.mongodb.initialize-schema=true spring.data.mongodb.uri=mongodb://raguser:raguser@localhost:27017/admin spring.data.mongodb.database=rag_store spring.ai.vectorstore.mongodb.indexName=vector_index spring.ai.vectorstore.mongodb.collection-name=rag_store
8. Conclusion
In conclusion, building a Retrieval-Augmented Generation (RAG) app using MongoDB and Spring AI represents a significant advancement in developing intelligent, context-aware applications. This tutorial has walked you through the essential steps, from setting up the necessary dependencies and configuring your environment, to implementing the core components such as the embedding model, similarity search, and generative response mechanism. By leveraging MongoDB’s robust data management capabilities and Spring AI’s powerful processing tools, you can create a seamless system that efficiently handles user queries and provides highly relevant, contextually enriched responses.
Throughout this process, the integration of MongoDB Atlas for storing and retrieving high-dimensional vectors has demonstrated the importance of efficient data handling in achieving rapid and accurate similarity searches. Meanwhile, Spring AI’s role in orchestrating the embedding and generation processes has highlighted the value of combining advanced AI techniques with robust application frameworks. The careful configuration of these components ensures that your RAG app not only meets performance requirements but also delivers a superior user experience.
Ultimately, this RAG app showcases how modern technologies can be synergized to solve complex problems in natural language processing and information retrieval. By following this tutorial, you have laid a strong foundation for building applications that understand and respond to user needs in a dynamic and meaningful way. The skills and knowledge gained here will be invaluable as you continue to explore and develop in the ever-evolving landscape of AI and data-driven applications.
6. Download
You can download the full source code of this example here: Building a RAG App Using MongoDB and Spring AI
